the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 05 Jul 2023
| 05 Jul 2023
Uncertainty growth and forecast reliability during extratropical cyclogenesis
Mark J. Rodwell
Heini Wernli
In global numerical weather prediction, the strongest contribution to ensemble variance growth over the first few days is at synoptic scales. Hence it is particularly important to ensure that this synoptic-scale variance is reliable. Here we focus on wintertime synoptic-scale growth in the North Atlantic storm track. In the 12 h background forecasts of the Ensemble of Data Assimilations (EDA) from the European Centre for Medium-Range Weather Forecasts (ECMWF), we find that initial variance growth at synoptic scales tends to be organized in particular flow situations, such as during the deepening of cyclones (cyclogenesis). Both baroclinic and diabatic aspects may be involved in the overall growth rate. However, evaluation of reliability through use of an extended error–spread equation indicates that the ECMWF ensemble forecast, which is initialized from the EDA but with additional singular vector perturbations, appears to have too much variance at a lead time of 2 d and that this over-spread is associated with cyclogenesis situations. Comparison of variance growth rates and reliability with other forecast systems within The International Grand Global Ensemble (TIGGE) archive indicates some sensitivity to the model or its initialization. For the ECMWF ensemble forecast, sensitivity experiments suggest that a large part of the total day-2 spread in cyclogenesis cases is associated with the growth of EDA uncertainty, but up to 25 % can be associated with the additional singular vector perturbations to the initial conditions and up to 25 % with the representation of model uncertainty. The sensitivities of spread to resolution, the explicit representation of convection, and the assimilation of local observations are also considered. The study raises the question of whether the EDA now successfully represents initial uncertainty (and the enhanced growth rates associated with cyclogenesis) to the extent that singular vector perturbations could be reduced in magnitude to improve storm track reliability. This would leave a more seamless forecast system, allowing short-range diagnostics to better help improve the model and model-uncertainty representation, which could be beneficial throughout the forecast range.
- Article
(15171 KB) - Full-text XML
- BibTeX
- EndNote





The chaotic nature of the atmosphere, with its large sensitivity to small perturbations (Sutton, 1954; Lorenz, 1963, 1972), has necessitated the development of probabilistic approaches to forecasting. In a “reliable” probabilistic forecast system, when aggregated over many forecasts, the issued probabilities for a given weather event should match the outcome frequencies (Sanders, 1958). The event could be, for example, that the temperature will be below 0 ∘C at a given location. Forecast reliability implies that, of all the times that a forecast probability p (e.g. p=0.5) is issued for the given event, the event happens a fraction p of the time (to within sampling uncertainty). Reliability is clearly important for forecast users because it means that they can make unbiased decisions (e.g. Rodwell et al., 2020). In addition to reliability, a probabilistic forecast system needs to be “sharp” – issuing probabilities as close to either 0 or 1 as possible. A forecast system which always issues the (sample) climatological probability for an event will be perfectly reliable, but, in general, it will not be sharp. Conversely, a single deterministic forecast can only issue probabilities of 0 or 1, so it will be completely sharp but cannot be perfectly reliable in the face of chaotic error growth. The goal of probabilistic forecasting is, thus, to maximize the sharpness of the predictive distributions subject to reliability (Gneiting and Raftery, 2007). A key question of practical importance is how can this goal be achieved or worked towards. An issue here is that the same forecast probability p can arise from very different courses of events. For example, a 6 d forecast probability for cold weather over Europe might be dependent on the decay of an existing blocking situation or might be dependent on the development of mesoscale convection over North America earlier in the forecast (Rodwell et al., 2013). The same probabilities can thus rely on the abilities of the forecast model to represent very different phenomena and their associated uncertainties. Rodwell et al. (2018) argued that it does not make sense to group such forecasts together. Instead, they suggest that a focus on short-range flow-dependent reliability (and a reduction of initial condition uncertainty) could represent a practical path to more skilful (more reliable and sharp) probabilistic forecasts.
This study focuses on extratropical cyclonic flow types and their intensification within the North Atlantic storm track. An example based on European Centre for Medium-Range Forecasts (ECMWF) Re-Analysis version 5 (ERA5; Hersbach et al., 2020) is given in Fig. 1. A little earlier than shown in Fig. 1, on 26 November 2019, the cyclone had begun to develop over the Midwestern United States. A day later, it had reached the Great Lakes with a central pressure at mean sea level (PMSL) of about 990 hPa. At 12:00 UTC on 28 November (Fig. 1a), the cyclone reaches the North American east coast with a similar PMSL intensity (grey contours). There is a cutoff in potential vorticity on the θ=315 K isentrope (P315, thick black contour) aloft and intense surface rainfall (shading) in the region of ascent identified as a warm conveyor belt (WCB; red hatching, following the approach of Wernli and Davies, 1997; Madonna et al., 2014). One day later (Fig. 1b), the cyclone strongly deepens to below 974 hPa as it moves slowly out into the Atlantic. Intense precipitation continues in the WCB ascent regions along the cold and bent-back fronts. In the next 24 h, the cyclone remains stationary, and it deepens further to below 970 hPa (Fig. 1c). The WCB and associated band of intense precipitation now extend from about 25 to 55∘ N, and the P315 pattern attains the classical structure of a mature cyclone, with a large-amplitude trough–ridge dipole up- and downstream of the surface cyclone, respectively. The heterogeneity of the precipitation rate along the WCB is reminiscent of the occurrence of embedded convection (Oertel et al., 2020). The example emphasizes the strong deepening (cyclogenesis) of the system off the North American east coast and its combined baroclinic and diabatic character. This case and another which is not shown here were chosen for sensitivity studies because they were quite clean, without being strongly affected by other flow perturbations in their environment, and because they involved both baroclinic and WCB aspects. However, the rate of deepening and the growth of uncertainty during the forecast were not considered in the choice. While these case studies are useful in several ways, the evaluation of forecast reliability is based here on cyclogenesis events over a whole season.
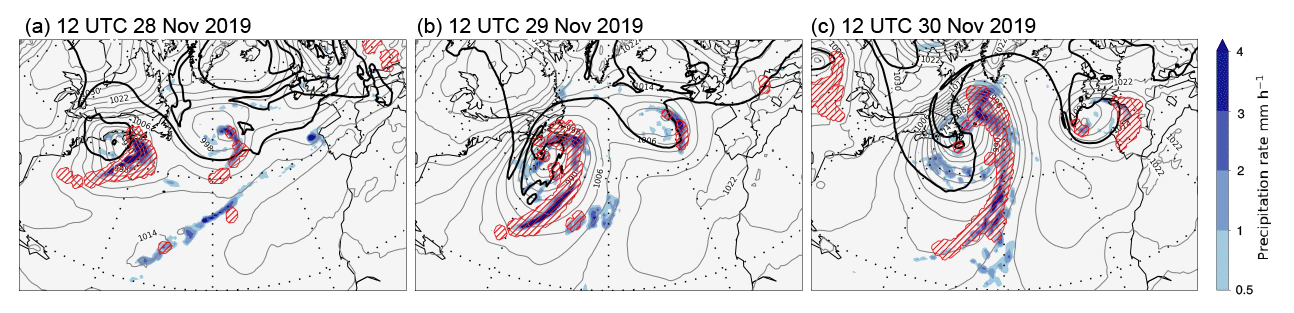
Figure 1Synoptic overview, based on ERA5 reanalyses, of a North Atlantic cyclogenesis event at 12:00 UTC on (a) 28 November, (b) 29 November, and (c) 30 November 2019. Shown are PMSL (grey contours at intervals of 4 hPa), surface precipitation accumulated over the previous hour (colour shading, in mm h−1), the P315=2 PVU contour indicating the tropopause on 315 K (thick black contour), and the WCB ascent region (red hatching). WCBs are identified as 48 h trajectories that ascend from the lower troposphere by more than 600 hPa (e.g. Wernli and Davies, 1997; Madonna et al., 2014), and the ascent region corresponds to the envelope of the horizontal positions of all WCB trajectories, initialized every 6 h, that are located between 800 and 500 hPa at the indicated time (corresponding approximately to their mid-ascent time).
It has been shown that dry low-resolution singular vectors identify baroclinic structures as the flow features leading to the largest day-2 uncertainty growth in the linear regime (Molteni and Palmer, 1993). The first objective for the current study is to investigate whether cyclogenesis events can coordinate strong growth of forecast uncertainty when moist processes are included (Hoskins and Coutinho, 2005) and the non-linear forecast model is run at much higher resolution. For example, does cyclogenesis act to reduce sharpness, and thus markedly shift forecast probabilities away from the desired values of 0 and 1? To explore this possibility, 12 h exponential growth rates are quantified following Rodwell et al. (2018) and related to dynamical and diabatic sources. The possibility that there is synoptic-scale coordination of uncertainty growth is interesting. Whether this hints at an intrinsic property of the atmosphere, or is dependent on the formulation of the forecast system, is explored by comparing models within The International Grand Global Ensemble (TIGGE; Bougeault et al., 2010) archive.
Probabilistic weather forecasts are generally based on ensemble techniques, whereby a set (or ensemble) of initial conditions, representing the uncertainty in the current state, is used to initialize an ensemble of numerical model forecasts (Palmer et al., 1992; Molteni et al., 1996). The variance of the ensemble, which generally grows with lead time, is then a measure of forecast uncertainty. Under various assumptions (Stephenson and Doblas-Reyes, 2000), a consequence of reliability is that the truth should be statistically indistinguishable from any ensemble member (Hamill, 2001; Saetra et al., 2004), and hence the squared difference between the truth T and the forecast ensemble mean should match the ensemble variance , when averaged over a sufficiently large set of forecasts: (Leutbecher and Palmer, 2008). This is often known as the “error–spread equation”. Note that a circumflex is used to indicate an estimator throughout this study, and an overline here indicates a mean over forecast initial times.
The maintenance of reliability during synoptic-scale uncertainty growth is particularly important in weather prediction because these scales become the largest contributor to global ensemble variance over the first few days of the forecast (Tribbia and Baumhefner, 2004, and also in the current study). The second objective for this study is thus to evaluate how well the ensemble system maintains short-range (2 d) reliability within the North Atlantic storm track and, with the help of a flow clustering technique, specifically during cyclogenesis events. To do this, an extended version of the error–spread equation, which takes account of bias and uncertainties in our estimation of T, is evaluated. Again the TIGGE archive is used to investigate sensitivity to forecast system formulation.
The final objective of this study is to quantify the impacts of individual aspects of the ECMWF ensemble configuration on forecast uncertainty during cyclogenesis. The aspects include the initial uncertainty, singular vector perturbations, model uncertainty, convective parameterization, increased model resolution, and the assimilation of observational data within the vicinity of the cyclogenesis event.
The study is structured as follows. Section 2 details the models, data, and methodologies used. Section 3 quantifies uncertainty growth rates, with particular application to cyclogenesis (objective 1). Section 4 evaluates forecast reliability, with application to seasonal means in the North Atlantic storm track region, and when composited on cyclogenesis cases (objective 2). Section 5 investigates the sensitivity of forecast uncertainty to aspects of the ECMWF forecast system during cyclogenesis (objective 3). A summary, conclusions, and discussion about prospective research are given in Sect. 6. The Supplement includes animations of uncertainty growth rates.
This study makes use of several models, data sets, and methodologies. These are described here for reference.
2.1 The ECMWF ensemble assimilation and forecast system
The underlying Earth system model for the ECMWF Ensemble of Data Assimilations (EDA; Isaksen et al., 2010; Lang et al., 2019) and ensemble forecast (ENS; Palmer et al., 1992; Molteni et al., 1996) use spherical harmonics to compute much of the dynamics, with physical parameterizations computed in grid-point space. Of particular interest here is the parameterization of convection, which was originally based on Tiedtke (1989) but includes revisions to entrainment and coupling with the large scale (Bechtold et al., 2008; Hirons et al., 2013) and improvements in the diurnal cycle of convection through use of a modified convective available potential energy (CAPE) closure (Bechtold et al., 2014).
The 50-member EDA used here has a nominal horizontal grid resolution of ∼16 km. More specifically, in the final EDA iteration, the underlying non-linear model retains a triangular configuration of spherical harmonics with total wavenumbers ⩽639 and uses a cubic octahedral grid so that four grid points represent the smallest waves (the resolution is thus summarized as TCo639). It has 137 levels in the vertical (L137) and uses a 12 min time step. The EDA employs 4D variational data assimilation (4DVar, Rabier et al., 2000); in addition to the full non-linear model, this uses tangent-linear and adjoint versions along with observation operators to extract the information content from many millions of conventional and satellite observations during each 12 h analysis cycle. This is done by first screening observations and correcting them using variational bias correction (VarBC, Dee, 2004). For each EDA member, the observations are then randomly perturbed to simulate observation uncertainty (Isaksen et al., 2010). The background (or first-guess) for a given EDA member is the non-linear forecast initialized from the same member's previous analysis. The estimated uncertainty in this forecast is based on the variances and correlations between the ensemble of background forecasts, with a climatological contribution to correlations for improved stability. For each EDA member, 4DVar combines its background forecast and perturbed observation set in a way that is consistent with the estimated uncertainties in the background (Bonavita et al., 2016) and observations (Geer et al., 2018). An additional unperturbed EDA member, with no perturbations to the observations, is also made.
The EDA is used to initiate a 50-member ENS, with resolution TCo639, L91, and a 12 min time step. Initial conditions are re-centred on a more recent (“early delivery”) unperturbed high-resolution (HRES) 4DVar analysis. Singular vector (Molteni and Palmer, 1993; Leutbecher and Lang, 2014) perturbations are added to the initial conditions as a pragmatic means of boosting ENS spread over the first 2 d. A model uncertainty parameterization, which partly aims to represent scale interactions with (missing) sub-grid-scale variations, is important for the general growth of ENS spread into the medium range (e.g. to day 10). Here, this model uncertainty representation is based on “stochastic perturbation to physical tendencies” (SPPT, Buizza et al., 1999), which represents a perturbation to the total physical tendency, and is applied throughout the forecast range. Note that SPPT is also applied to the non-linear model in the perturbed members of the EDA, but there are no singular vector perturbations in the EDA.
The sensitivity experiments discussed in Sect. 5 are based on cycle 46r1 of the ECMWF Integrated Forecasting System (IFS). This cycle was operational from 11 June 2019 to 20 June 2020, and prior information for the experiments comes from the operational EDA. In the higher-resolution ∼4 km ENS experiment, the model is run in a single numerical precision (Ván̆a et al., 2017; Lang et al., 2021) with resolution TCo2559 L91 and a 4 min time step.
2.2 Other ensemble forecast systems in the TIGGE archive
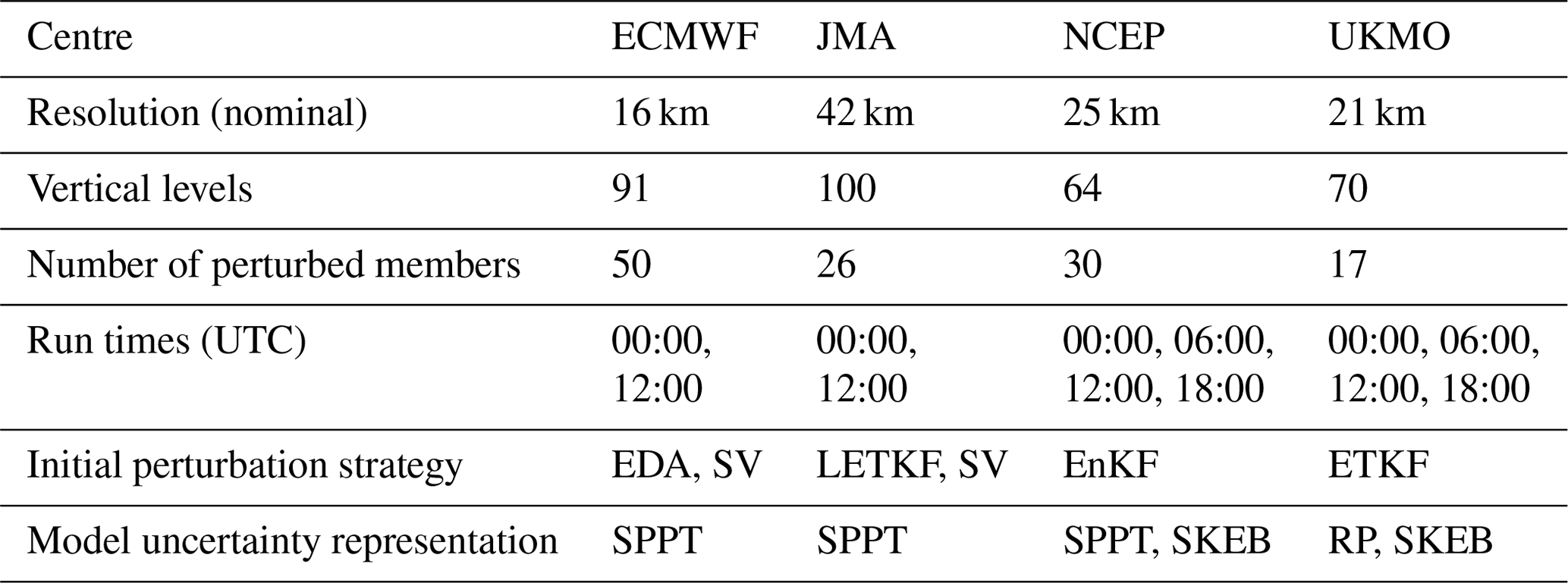
In comparisons with ensemble forecasts from other centres, all data are retrieved from the TIGGE archive (Bougeault et al., 2010; Swinbank et al., 2016; Parsons et al., 2017), which currently contains global ensemble forecasts from about a dozen of the world's operational forecasting centres (12 centres were present on 1 September 2021). These forecasts are available a few days behind real time and are a valuable resource for diagnostic studies. Three other TIGGE models are compared with the ECMWF model. These are from the Japan Meteorological Agency (JMA), the United States National Centers for Environmental Prediction (NCEP), and the United Kingdom Met Office (UKMO). Salient details of these four ensemble forecast systems are presented in Table 1, and further documentation is available from the TIGGE website (https://confluence.ecmwf.int/display/TIGGE). Here, comparisons are based on the common run times of 00:00 and 12:00 UTC.
Table 1Details of the four TIGGE models used in this study, valid during the period of investigation. EDA – ensemble of 4DVar (Isaksen et al., 2010), 4DVar – 4D variational data assimilation (Rabier et al., 2000), EnKF – ensemble Kalman filter (Evensen, 1994), ETKF – ensemble transform Kalman filter (Bishop et al., 2001), LETKF – local ensemble transform Kalman filter (Hunt et al., 2007), SPPT – stochastic perturbation to physical tendencies (Buizza et al., 1999), SV – singular vector (Molteni and Palmer, 1993), RP – random parameter (McCabe et al., 2016), SKEB – stochastic kinetic energy backscatter (Shutts, 2004).
2.3 The extended error–spread equation
In Sect. 1, the error–spread equation was discussed. This equation is not precise enough for application at the short lead times of interest here because uncertainty in our knowledge of the verifying truth is not negligible in the calculation of forecast error. It is also important to consider forecast and analysis bias (arguably this can be important at all lead times). To account for these aspects, the observation-space reliability assessment of Rodwell et al. (2016) employed an extended error–spread equation. Here we modify their equation to reflect the fact that uncertainty in the truth is estimated by the variance of the verifying analysis, rather than the estimated variance of the observation error. Let and be the (imperfect) forecast and verifying analysis distributions, respectively, for forecast initial time tj, . The ensembles give us m samplings of these distributions. Let be the difference between the ensemble mean of the forecast and the ensemble mean of the analysis , and write and for the forecast and verifying analysis ensemble variances, respectively. Then, using an overline here to indicate a mean over the n forecast times, the extended error–spread equation for n forecasts of an ensemble with m members can be written as
where the various terms have been named for future reference (superscript 2 indicates that these are in squared units). In addition to the error and spread terms, there are now terms reflecting analysis uncertainty, squared bias (associated with mean differences between the forecast and analysis), and a residual , which closes the budget (this can be negative or positive and written as the mean of the Rj, which close the budget for each value of j, for given mean bias estimate ). The contents of the residual are discussed more fully in Appendix A, following a full and consistent derivation of Eq. (1). The residual is seen to represent the mean deficit in the combined forecast and analysis variance and, potentially, the flow-dependent variance in forecast bias. As lead time increases beyond 12 h, one might expect the bias and residual to become dominated by deficiencies in the forecast. Hence this equation is useful for monitoring progress towards the goal of probabilistic forecasting: the spread2 relates to ensemble sharpness, and the residual(2) and bias2 relate to the ensemble reliability. A flow-dependent application of Eq. (1), which is possible because it is valid at short lead times, should also diminish the impact of flow-dependent variations in forecast bias. Here, the equation is applied to 2 d forecasts of geopotential height at 250 hPa (Z250) and temperatures at 500 hPa (T500), started at 00:00 and 12:00 UTC, valid during the December–February 2020/2021 season (DJF 2020/2021).
For display purposes the terms in Eq. (1) can be put into more understandable units by taking their square roots, signified by removing the superscript 2 label. Note that the square root of bias2 is bias (with its correct sign). Since can be positive or negative, residual is plotted to retain the sign. While smaller terms will look more important than they are in the squared budget, the residual still correctly indicates spread deficiencies. Statistical significance is determined (at the 5 % level with a t test) from the un-rooted terms (except for bias2, which must be determined in its non-squared form).
Note that the observation-space version of the extended error–spread equation (Rodwell et al., 2016) would probably represent a more fundamental evaluation of the forecast system, if assigned observation error variances aimed to reflect their true values. In reality, some observation error variances can be inflated to account for representativeness error (Rennie et al., 2021), observation error correlations, or when associated with non-linear observation operators. This can lead to a large residual term for a given observation type, even if the resulting analyses and forecasts are reliable in model space. Hence the current model-space application represents a complementary approach, which can be more readily applied to a range of models and lead times, and which can be used to assess ensemble initialization aspects.
2.4 K-means clustering
This study aims to evaluate ensemble reliability during cyclogenesis events, and so a means of focusing on such events is required. The method used is K-means clustering (Hartigan and Wong, 1979), which seeks to minimize the sum of squared deviations from the relevant cluster mean. To identify cyclogenesis events in the analyses, the clustering is applied in 30∘ longitude × 20∘ latitude boxes at 00:00 and 12:00 UTC during DJF 2020/2021 jointly to the fields of Z250 and zonal and meridional wind at 850 hPa (u850, v850) at step 0 from the control forecast, and ensemble mean 12 h accumulated total precipitation from the previous forecast (so the end of the accumulation period corresponds to the time of the circulation fields). It is thought that these fields should be able to capture upper-tropospheric Rossby waves, baroclinic structures, and associated diabatic processes. It is the ability to cluster on structures which motivated the choice of the K-means approach. The choice was made to find three clusters, since it was thought that these would provide sufficient degrees of freedom to differentiate the local synoptic-scale structures while giving large-enough clusters to obtain statistical significance. Each field is on a regular F32 (∼300 km) Gaussian grid, standardized (about its area and temporal mean), and root–cosine–latitude-weighted prior to application of the clustering algorithm (total precipitation is standardized by dividing by the square root of its area- and temporal-mean-squared value). This is to give approximately equal weight to each field and sub-region. Three random date/times (out of the 180 date/times available within the season) are used to initialize the clusters. Since there is no guarantee that the algorithm will identify the optimal solution, it was initialized 100 times. No reduction in the sum of squared deviations from the cluster means was found after the first ∼ 5 such initializations – indicating that the final solution is optimal.
2.5 Potential vorticity
A useful quantity for this study is isentropic potential vorticity (IPV; Hoskins et al., 1985), . Here, g is the gravitational acceleration, f is the Coriolis parameter, p is pressure, θ is potential temperature, and is the isentropic vorticity, where k is the local unit vertical vector, ∇θ is the horizontal gradient operator on an isentropic surface, and v is the horizontal wind vector. IPV is usually measured in PV units (PVU) with 1 PVU m2 s−1 K kg−1. A key advantage of using IPV here is that its tendencies due to dynamic and diabatic effects can be readily separated:
where 𝒟 represents the effects of non-conservative (diabatic and frictional) processes (Holton and Hakim, 2013, Eq. 4.50). IPV is thus conserved following the horizontal flow on an isentrope in the absence of such processes. This study will use P315, the IPV on the 315 K isentrope, which typically intersects the dynamical tropopause (P = 2 PVU) during winter in the midlatitudes.
2.6 The Lagrangian growth rate of forecast uncertainty
It is useful to quantify the rate of growth of uncertainty, to relate this to local and remote sources and investigate its flow dependence. The local exponential growth rate of ensemble spread can be estimated as , where is the ensemble standard deviation of some atmospheric parameter field X and t is the forecast lead time. Rodwell et al. (2018) observed that, for X=P315 in the North Atlantic storm track region, a large component of the local growth rate over the first 12 h appeared to be associated with the advection of uncertainty. This led them to calculate a material Lagrangian growth rate (LGR) following the ensemble-mean wind:
The first line of Eq. (3) follows Rodwell et al. (2018), and the second line is deduced in this study, using Eq. (2) and taking inspiration from Baumgart and Riemer (2019). A derivation is given in Appendix B, although the equation is quite self-explanatory. An overline here represents a mean over the ensemble members, and a prime denotes a deviation from the ensemble mean. The variance estimator for P is then given by . The use of the ensemble-mean horizontal wind in the definition of LGRP makes most intuitive sense when very short lead times are considered, so that all ensemble members are representing essentially the same synoptic flow situation. The two covariance terms on the second line provide a useful glimpse at the processes driving the material growth rate. The first is proportional to the covariance of PV deviations P′ with the deviations in local diabatic and frictional PV sources 𝒟′. The second is proportional to the covariance of PV deviations with the advection of PV by the deviation winds v′.
The normalization in Eq. (3) by , to give the exponential form of the growth rate, allows comparison of ensembles with differing magnitudes of initial uncertainty. Note that the corresponding exponential growth rate of the ensemble variance is simply twice that of the standard deviation. Equation (3) will be discussed in the context of cyclogenesis in Sect. 3.1.
Baumgart and Riemer (2019) investigated the remote and dynamical sources of variance growth over a 10 d forecast using a slightly different equation – their Eq. (8). To deal with the large redistribution of variance, they choose to disregard the flux divergence term. This leaves an additional source of variance associated with wind divergence. In view of the potential for local cancellations, the choice of strategy may depend on the application. Here, the divergence of ensemble mean winds at a 12 h lead time is likely to be well constrained by the observations and of less concern for our evaluation goal.
To concentrate on growth rates at synoptic scales (but due to interactions at all scales), the plotted Lagrangian growth rates are smoothed with a synoptic spatio-temporal filter. Details of this filter and other technical information are given in the following paragraph.
LGRP is constructed using the 12 h non-linear background forecasts from the EDA (so no lead times are greater than 12 h), started at 06:00 and 18:00 UTC. Calculations use centred means and differences between consecutive hourly lead times. For the upper-tropospheric fields, P315 and winds at θ=315 K (v315) are first interpolated to an N32 reduced Gaussian grid (with 32 latitudes between the pole and Equator). The spatial derivatives within the advection term in LGRP are calculated using spectral transforms to and from a T42 spherical harmonic representation. Note that N32 is sufficient to avoid aliasing of higher harmonics of the quadratic advection term into the T42 representation. The 12 fields of P315 and LGRP are then concatenated over EDA cycles and smoothed with a synoptic spatio-temporal filter. This multiplies spectral coefficients with total wavenumber by so that scales larger than ∼700 km are retained. The filter also includes a 24 h running mean. The nominal validity time is at the centre of the running-mean window – placing the final fields back on the full hours. The resulting time series of fields can be used to produce animations of P315 which “shadow” (remain within the background uncertainty of) the true synoptic evolution of the flow, with LGRP highlighting the initial (∼12 h) rate of divergence of the ensemble about the synoptic state. For the lower-tropospheric fields shown in the same plots, winds and specific humidities at 850 hPa (v850, q850) and surface pressure p*, all from the background forecasts of the control EDA member, are first interpolated to an O32 octahedral reduced Gaussian grid (with 32 latitudes between the pole and Equator). Values are set to “missing” where the 850 hPa surface is below the land surface (where hPa), and the moisture flux is calculated as . The ensemble mean total precipitation rate is used to indicate where precipitation is likely to occur. This is obtained on a higher-resolution O80 octahedral grid so that grid points give a good symbolic representation (stippling) of rainfall when plotted. After similar concatenation of EDA cycles, the lower-tropospheric fields are smoothed with a 24 h running mean.
Since the required fields are not available in TIGGE, when comparing with other models in Sect. 3.2, the pragmatic decision is made to calculate the Lagrangian growth rate LGR for Z=Z250, where ∇p is the horizontal gradient operator on the pressure surface. LGRZ is constructed using the first 12 h of each model's ensemble forecasts started at 00:00 and 12:00 UTC. Calculations use centred means and differences between consecutive 6-hourly lead times (0 h, 6 h, 12 h). All other details are the same as for LGRP, except that the plotted Z250 field is not spatially smoothed (it is considered already a synoptic-scale field). Note that humidity fluxes could not be calculated for the UKMO model as specific humidity data were not available from TIGGE. The resulting time series of fields can again be used to produce animations (hourly frames being derived using linear interpolation between the 6 hourly fields)
This study starts with an investigation of the uncertainty growth during cyclogenesis. It makes use of the Lagrangian growth rate discussed in Sect. 2.6. First, initial growth rates within the background forecasts of the EDA are discussed. After this, a comparison is made with other models in the TIGGE archive.
3.1 Uncertainty growth in the EDA
Figure 2 is a synoptically filtered analysis of the event shown in Fig. 1, valid at the mid-point of the cyclogenesis (Fig. 1b). The baroclinic westward tilt with height is evident from the positioning of the upper-tropospheric P315=2 PVU contour (red) and the lower-tropospheric v850 wind vectors. Ahead of the trough, there are strong moisture fluxes (where vectors are coloured blue) and strong precipitation (black dots). The P315=2 PVU contour also indicates upper-tropospheric ridge development downstream of the trough.
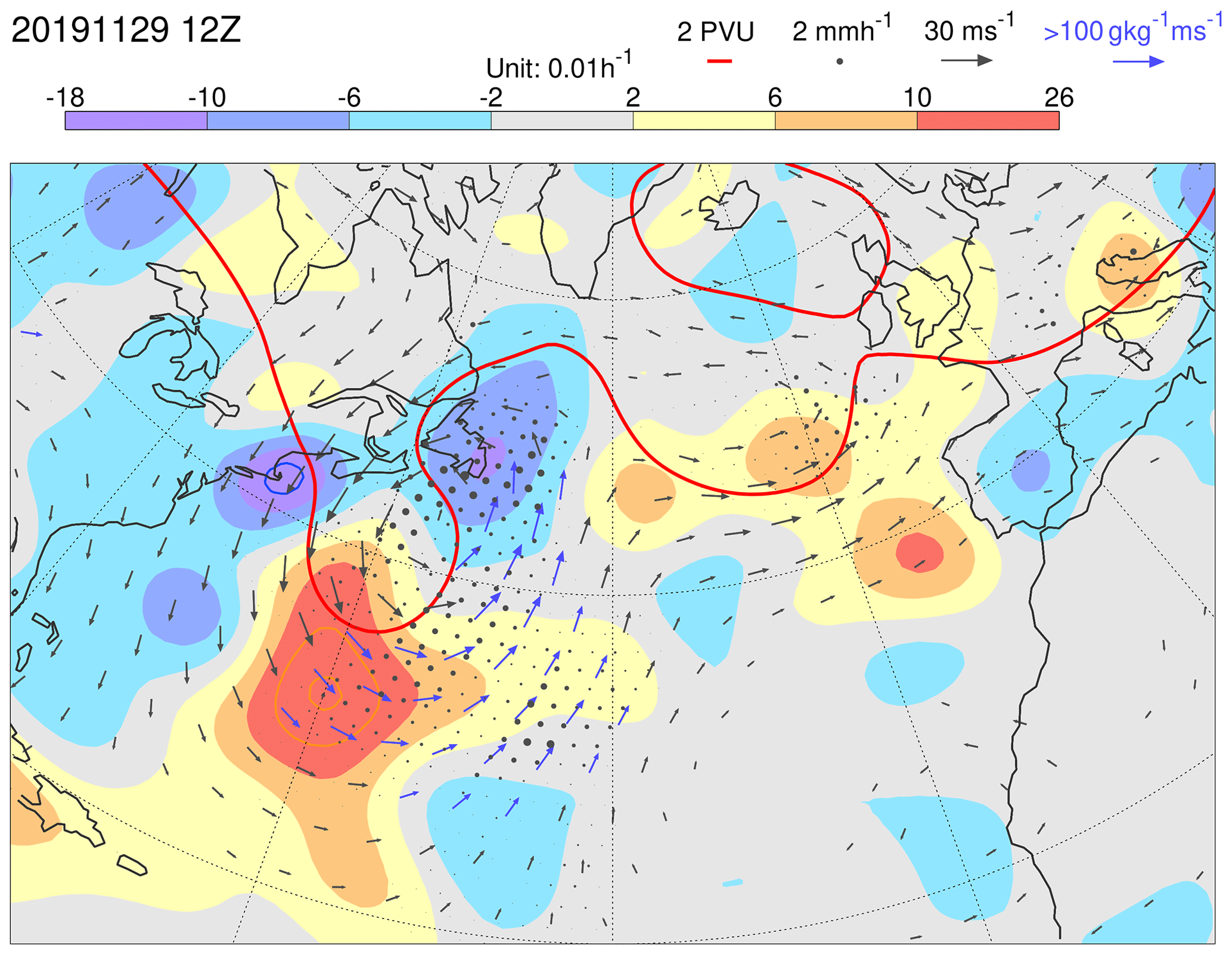
Figure 2Growth rate LGRP for P315 in EDA background forecasts (shaded), centred at 12:00 UTC on 29 November 2019. Note that orange and blue contours extend the shading scheme, with the same interval. In these cases, the most extreme values are indicated at the ends of the colour bar. Also shown, for the unperturbed EDA member, are P315=2 PVU (red contour) and v850 (vectors, which are plotted blue if the moisture flux at 850 hPa exceeds 100 g kg−1 m s−1). The ensemble mean precipitation is indicated by black dots (with a radius proportional to the precipitation rate up to the maximum size at 2 mm h−1).
The Lagrangian growth rate LGRP (shaded) highlights uncertainty growth in excess of 0.18 h−1 at the southern extent of the upper-level trough. It is tempting to speculate that this strong growth rate corresponds to uncertainties in baroclinic development, as depicted in the image of Hoskins et al. (1985) – their Fig. 21b. That figure highlights the strengthening of upper-tropospheric PV anomalies due to advection by the equatorward winds induced from lower-tropospheric PV anomalies. The variance growth would thus be associated with the covariance of ensemble deviations in this advection with the upper-tropospheric PV deviations themselves . This process would thus be represented in the second LGRP source term on the second line of Eq. (3). Interactions within and between scales, represented in this non-linear source term, can produce initial uncertainty growth at synoptic scales because the EDA contains considerable variance power at spatial scales between about 100 and 2000 km (illustrative power spectra of T500 are presented in Fig. C1 in Appendix C). This may not be the case in predictability studies, where initial uncertainty is restricted to grid-point noise (Judt, 2018). See also Durran and Gingrich (2014) and Selz et al. (2022) for relevant discussions. Note that baroclinic development was not seen as the dominant process driving initial variance growth by Baumgart and Riemer (2019). They suggested that the strongest contribution to this source term is associated with local dynamical interactions between upper-tropospheric PV deviations and the winds that they induce.
Also evident in Fig. 2 are weaker negative LGRP values (where the ensemble is tending to converge in this Lagrangian sense) particularly in the ridge-building region above the northern part of the WCB (see Fig. 1b). It is possible that this could be associated with uncertainties in the erosion of the eastern edge of the upper-tropospheric trough, as depicted in the image of Ahmadi-Givi et al. (2004) – their Fig. 14b. That figure highlights the effect of mid-tropospheric latent heating on the leading edge of the upper-tropospheric PV anomaly. The variance reduction would thus be associated with the covariance of the strength of this erosion of PV with the upper-tropospheric PV deviations themselves . This process would be represented in the first LGRP source term on the second line of Eq. (3). Note that such an effect might be quite sensitive to the magnitude of diabatic perturbations introduced by the representation of model uncertainty.
The Supplement includes animations of similar plots to Fig. 2. They show fields of P315, v850, and precipitation, which effectively shadow the true synoptic evolution of the flow, with LGRP highlighting the initial (∼12 h) rate of divergence of the EDA background ensemble about the synoptic state. Synoptic features associated with large uncertainty growth rates are evident. The results highlighted in Fig. 2 are typical of many cases seen within the animations and often include strongly precipitating WCBs (with embedded convection; Grams et al., 2018; Oertel et al., 2020). Other common situations for strong growth rates (not investigated here, but consistent with previous studies) are during the extratropical transitions of tropical cyclones (Riemer and Jones, 2014) and within high CAPE situations over North America where mesoscale convection is likely to develop (Rodwell et al., 2013, 2018; Sun and Zhang, 2016). All these situations can lead over Europe to extreme precipitation (Grams and Blumer, 2015), blocking events (Rodwell et al., 2013) and, in deterministic forecasts (which can be thought of a single sampling of an ensemble distribution), “busts” or “dropouts” (Lillo and Parsons, 2017).
3.2 Uncertainty growth in TIGGE forecasts
The question arises as to how well the ECMWF growth rates discussed in Sect. 3.1 agree with the growth rates derived from the ensembles of other operational forecast centres. This question is explored using the first 12 h of ensemble forecasts within the TIGGE archive, for the models summarized in Sect. 2.2. As discussed in Sect. 2.6, growth rates are based on Z250 because the required fields are not available in the TIGGE archive. Figure 3 shows filtered LGRZ (shaded) for the TIGGE models centred on the same time as that shown in Fig. 2. Other fields shown are the same as in Fig. 2 except that Z250 is contoured in green. For ECMWF in the region of cyclogenesis, filtered LGRZ from the ENS (Fig. 3a) agrees quantitatively quite well with filtered LGRP from the EDA (Fig. 2), despite being growth rates of different fields, and despite the use of additional singular vector perturbations in the ENS. One difference of note for later might be that the maximum ENS growth rate is placed a little more towards the western side of the upper-level trough than is the case for the EDA growth rate (cf. Figs. 2 and 3a).
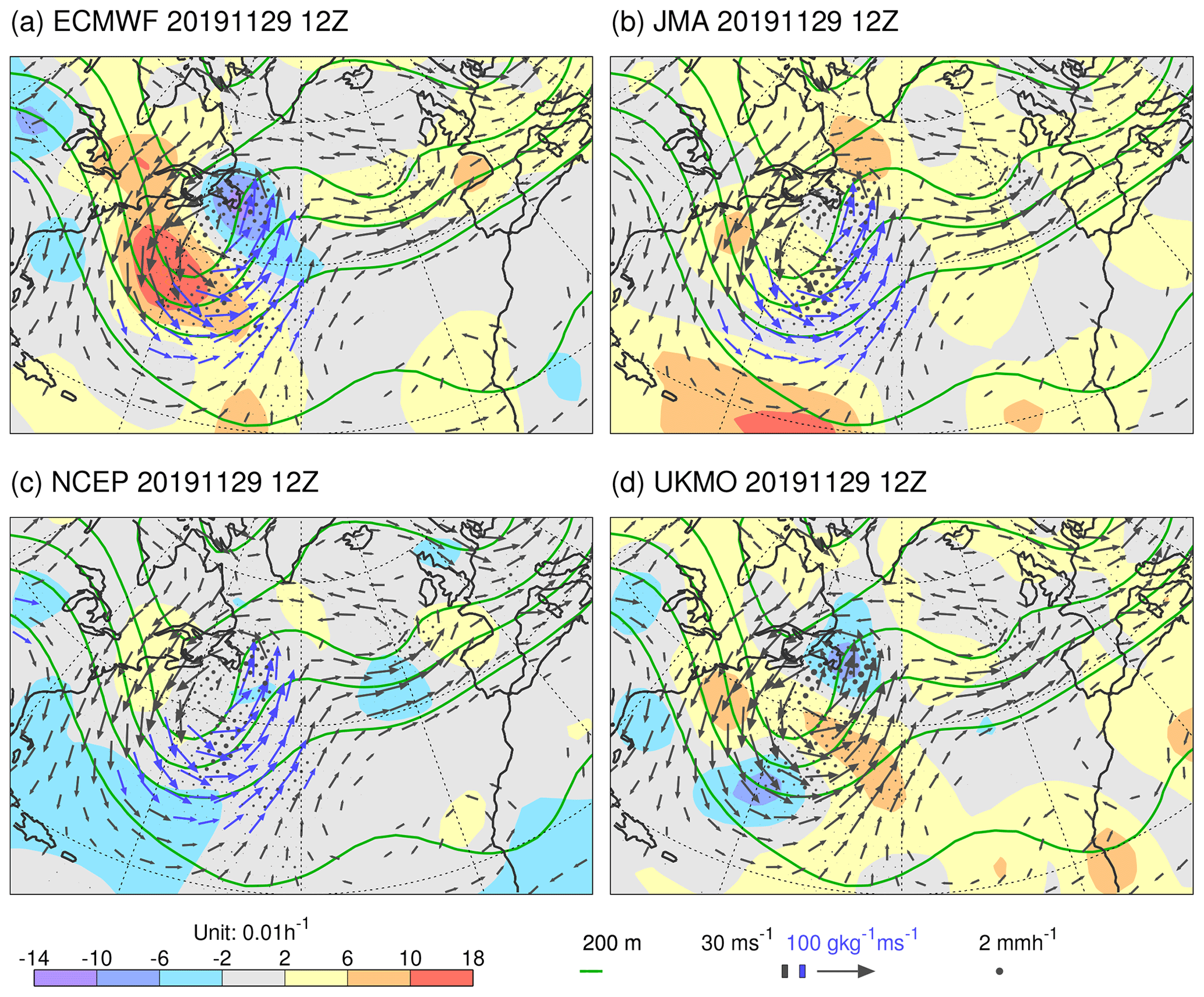
Figure 3Growth rate LGRZ for Z250 for TIGGE models (shaded), centred at 12:00 UTC on 29 November 2019. Note that orange contours extend the shading scheme with the same interval, where required. In these cases, the most extreme values are indicated at the ends of the colour bar. Also shown, for the unperturbed ensemble members, are Z250 (green contours) and v850 (vectors, which are plotted blue if the moisture flux at 850 hPa exceeds 100 g kg−1 m s−1). Ensemble mean precipitation is indicated by black dots, with a radius proportional to the precipitation rate up to the maximum size at 2 mm h−1. The models shown are from (a) ECMWF, (b) JMA, (c) NCEP, and (d) UKMO as discussed in Sect. 2.2.
Comparison amongst the centres in Fig. 3 indicates strong agreement in the analysis of the synoptic situation, as displayed in the fields of Z250, v850, moisture fluxes, and, to some extent, precipitation. Although there are commonalities, such as in the observational information available to each centre's data assimilation, this agreement suggests that the analyses shadow well the true synoptic evolution. Despite this agreement, the filtered LGRZ differs widely amongst the models in this example. Assuming this result carries over to LGRP, it suggests that there are differences in the source terms on the second line of Eq. (3). Looking over many examples (within the TIGGE animation for the DJF 2020/2021 season in the Supplement), the agreement can be better (see example in Fig. 4). Nevertheless, differences between the models' growth rates can be striking, with the ECMWF model tending to display the strongest values. The question arises as to whether the ECMWF growth rates are too strong in the vicinity of cyclogenesis. Is the ECMWF ensemble spread being over-inflated in these situations, with the consequent impact on forecast reliability and sharpness?
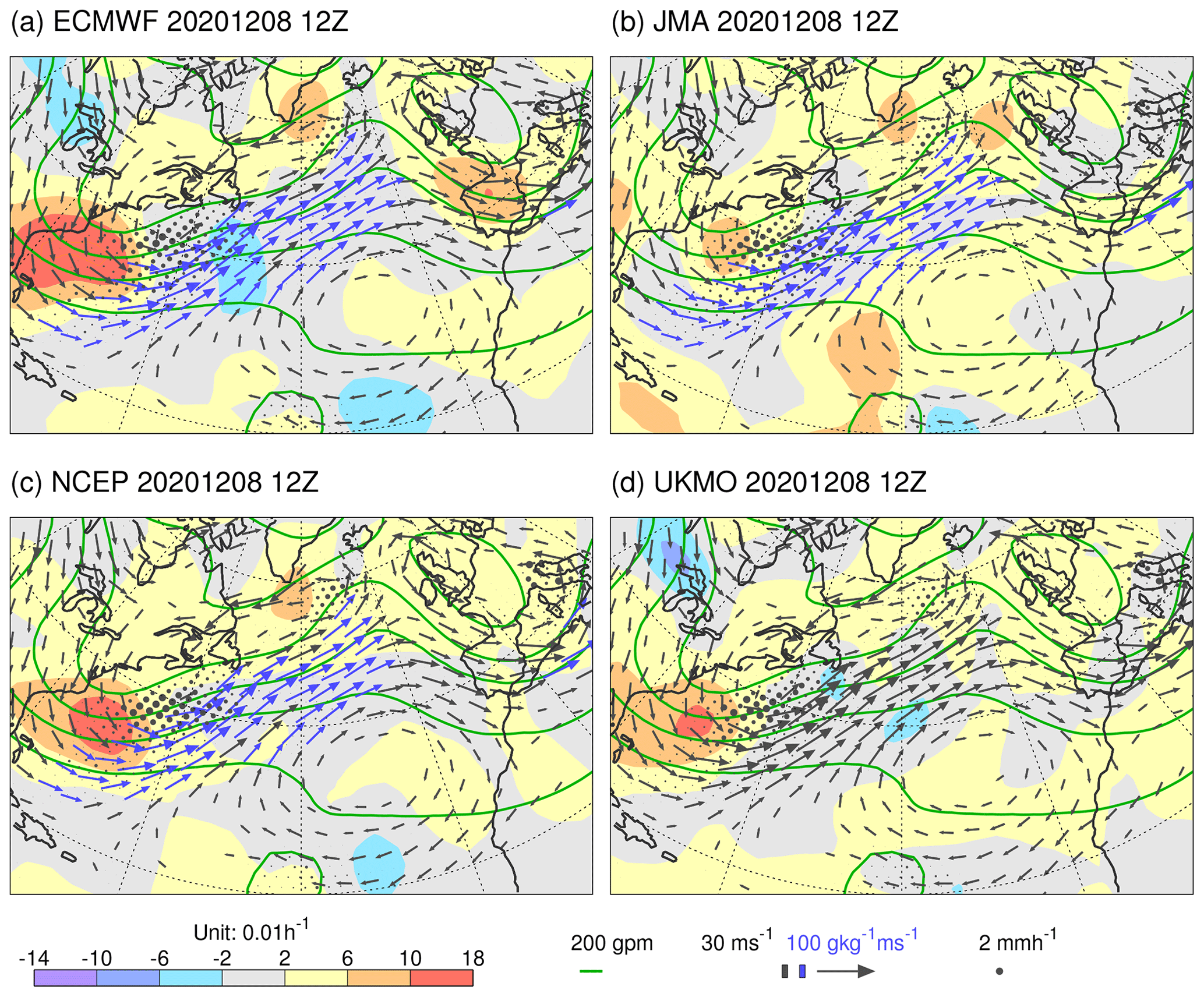
Figure 4As Fig. 3 but centred at 12:00 UTC on 8 December 2020. This situation also corresponds to an event of cyclone intensification off the North American east coast associated with a WCB.
The differences in the models' filtered LGRZ reflect differences in initialization procedures, differences in the representation of model uncertainty, and differences in the deterministic models themselves (summarized in Table 1). While it is difficult to evaluate these growth rates per se, it is possible to assess how well each ensemble system maintains short-range statistical reliability within the North Atlantic storm track. This is done in Sect. 4.1.
The concept of forecast reliability and the need to improve this in a flow-dependent sense was discussed in Sect. 1. As discussed in Sect. 2.3, the precision and short forecast ranges required for flow-dependent evaluation necessitate the use of an extended error–spread equation, Eq. (1), which accounts for bias and uncertainties in the verifying analysis. The residual in this equation estimates the sum of the deficits in forecast and analysis variance, plus a potentially non-negligible term representing flow-dependent variations in forecast bias. Hence a negative residual indicates a surplus in variance, while a positive residual can indicate a deficit in variance provided the flow-dependent variations in forecast bias are negligible or accounted for. In Sect. 4.1, the equation is applied to day-2 TIGGE forecasts verifying within the season DJF 2020/2021. In Sect. 4.2 and 4.3, flow dependence is considered by compositing on cyclogenesis cases.
4.1 Seasonal mean forecast reliability in the TIGGE ensembles
Figure 5 shows the (square-rooted) terms of the extended error–spread Eq. (1) for Z250 based on all day-2 ensemble forecasts verifying in DJF 2020/2021 from the ECMWF (top row), JMA (second row), NCEP (third row), and the UK Met Office (bottom row) ensembles. Focusing first on ECMWF (top), the North Atlantic winter storm track is evident as a region of enhanced ensemble spread (Fig. 5b). Even without the analysis uncertainty and bias contributions, the spread is larger than required to balance the error (Fig. 5a) – signifying over-spread in the storm track at day 2. Analysis uncertainty is also enhanced in the storm track region (Fig. 5c), and a statistically significant bias is seen over the east coast of North America. Confirmation of the over-spread is seen with the large negative residual (Fig. 5e). Note the different colour-bar convention for the bias and residual, which can take positive and negative values. Over the North American east coast, the squared budget Eq. (1) is roughly m2. Because analysis uncertainty and bias are not negligible here, the “reliable spread” (i.e. the spread required for a zero residual) in this region would actually be ∼13.42 m2, somewhat less than the 152 m2, which might be inferred from the standard error–spread relationship. Accounting for the variance of forecast bias would reduce further the reliable spread a little (see Sect. 4.3). In contrast, there is a positive residual over the subtropical North Atlantic (Fig. 5e). Whether this indicates insufficient spread to account for the elevated errors in this region (Fig. 5a) or is associated with variance in forecast bias is also discussed in Sect. 4.3. Note that Rodwell et al. (2018) indicated better reliability for the ECMWF ensemble, when averaged over a year and over the Northern Hemisphere. As part of the current study, but not shown here, this reflects compensating deficiencies elsewhere, a recent deterioration in ensemble reliability in the storm track, and the importance of accounting for bias and analysis uncertainty. These differences underscore the need for increased granularity (such as associated with flow dependence) in the evaluation of reliability.
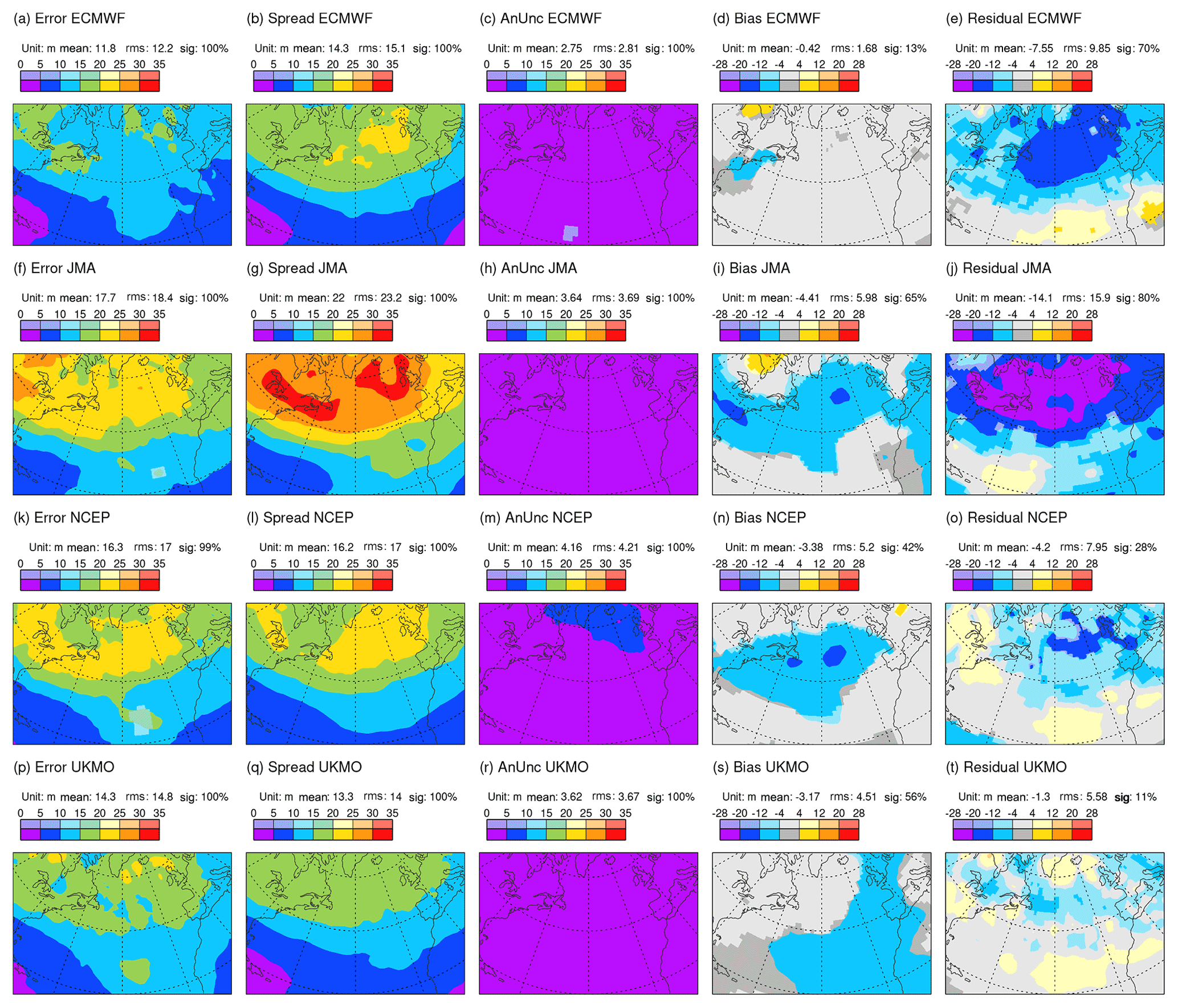
Figure 5Square roots of terms in the extended error–spread budget Eq. (1) for Z250 based on all day-2 forecasts verifying in DJF 2020/2021. Data come from the TIGGE archive for ECMWF (top row), JMA (second row), NCEP (third row), and UKMO (bottom row) ensembles. Note that the bias and residual, which can take positive and negative values, are shaded with a different interval to the other terms. Statistically significant values are shown with more saturated colours. Area means (for the area displayed) are indicated at the top of each panel (e.g. “sig: 85 %” means that 85 % of the area shown is significant at the 5 % significance level, using an auto-regressive AR(1) model to take account of serial correlation).
For the JMA ensemble during this season, day-2 error is larger than for ECMWF (cf. Fig. 5a and f), and the spread is increased by a larger amount (cf. Fig. 5b and g). Note that mean values and root-mean-square (rms) values, integrated over the area shown, are indicated above each panel in Fig. 5 – it is the rms values which are most appropriate for comparison. The analysis uncertainty and bias are also larger for JMA (cf. Fig. 5c, h and d, i). Consequently, the residual is more strongly negative (cf. Fig. 5e and j) – indicating more severe over-spread in this ensemble at this lead time. For the NCEP ensemble relative to ECMWF, a smaller increase in spread (cf. Fig. 5b and l) than in error (cf. Fig. 5a and k) leads to better variance reliability (cf. Fig. 5e and o), despite having larger analysis uncertainty and bias (cf. Fig. 5c, m and d, n). For the UKMO ensemble relative to ECMWF, error is larger (cf. Fig. 5a and p) and spread is reduced (cf. Fig. 5b and q) – leading to the best variance reliability of the four models (Fig. 5t), again despite having larger analysis uncertainty and bias (cf. Fig. 5c, r and d, s) than for ECMWF. Note that conclusions drawn in this section extend to other parameters (such as geopotential heights and temperatures at 500 hPa), other seasons, and other storm tracks and continue until the most recent check for the March–May season 2022 (not shown). With reference to Table 1, an interesting commonality of the two most over-spread systems (ECMWF and JMA) is the use of singular vector perturbations in their initial conditions. Puzzlingly, however, JMA appears to show weaker initial growth rates than ECMWF (see e.g. Figs. 3 and 4). Differences could be associated with the use here of an exponential growth rate and the larger initial uncertainty in the JMA forecast (variance in initial conditions ≈ variance in verifying analysis, so panel titles for Fig. 5c and f show that area-integrated initial variance is 72 % larger for JMA than for ECMWF).
To answer the question in Sect. 3.2, whether the ECMWF growth rates are too strong in the vicinity of cyclogenesis, it needs to be determined whether the negative residual in Fig. 5e is associated with a general level of over-spread or whether it can be linked to cyclogenesis events per se. In Sect. 4.2, cyclogenesis events are objectively identified, and then, in Sect. 4.3, the reliability assessment is repeated for these events.
4.2 Compositing cases of cyclogenesis
Here, the K-means clustering methodology (Sect. 2.4) is used to objectively identify cyclone events within the DJF 2020/2021 season, based on forecast step 0 fields of Z250, zonal and meridional components of v850, and ensemble-mean precipitation accumulated over 12 h periods ending at the times of the circulation fields. The first clustering region is located at the head of the North Atlantic storm track [80–50∘ W, 30–50∘ N] and contains 11 × 7 data points on the F32 grid. The rationale for choosing this region is that it corresponds to the North Atlantic hot spot for cyclone intensification (e.g. Wernli and Schwierz, 2006) and WCB activity (Madonna et al., 2014), and its size corresponds to a half-wavelength of a typical baroclinic wave.
Figure 6 (top row) shows the same fields as in Fig. 3 but averaged over the three sets of date/times obtained from the K-means clustering in this (indicated) region. Cluster 1 (Fig. 6a, 32 date/times) appears to capture a partially evolved cyclogenesis flow type off the east coast of North America, with a baroclinic westward tilt with height, intense horizontal moisture flux, and precipitation ahead. Despite being a somewhat diffuse average of events, the mean drop in analysed PMSL over the previous 2 d attains 14 hPa (not shown), which emphasizes the cyclogenesis interpretation. A general tendency for strong uncertainty growth rate at the southern extent of the upper-level trough is also evident. (Note that the growth rate is not used within the clustering algorithm since this could potentially bias the reliability assessment.) Cluster 2 (Fig. 6b, 75 date/times) shows a broader trough, weaker moisture flux, and possible cyclogenesis, displaced further downstream. Cluster 3 (Fig. 6c, 73 date/times) shows a diffuse ridge with a trough even further downstream and a surface anticyclone in the subtropical western North Atlantic.
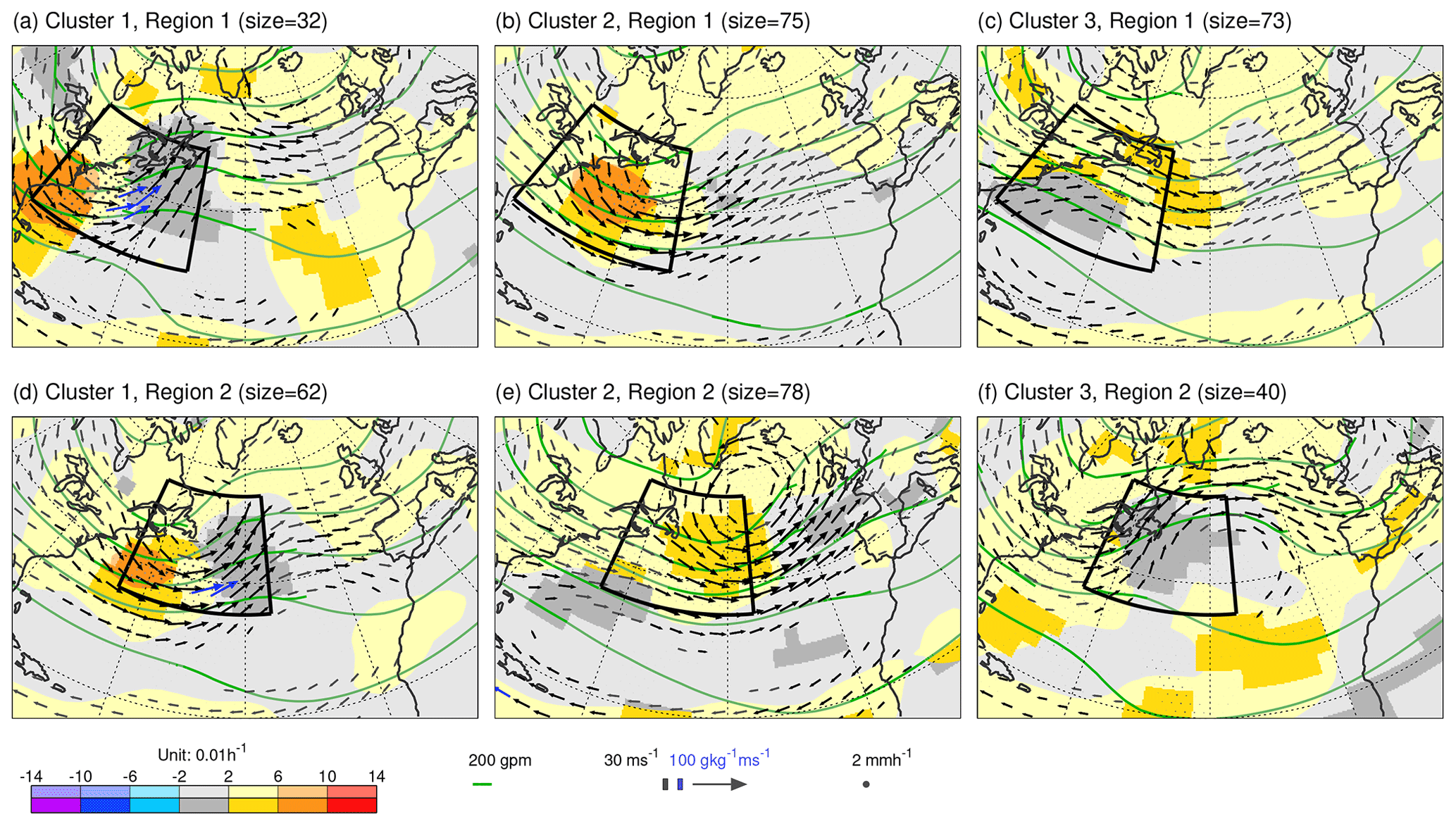
Figure 6Means over the date/times for the three clusters obtained from K-means clustering in the first (a–c) and second (d–f) region on the fields of Z250 (contours), u850 and v850 (vectors) from ECMWF control (unperturbed) forecasts at step 0, and ensemble mean 12 h accumulated precipitation (dots) valid (or end of accumulation) at 00:00 and 12:00 UTC within the period DJF 2020/2021. The two clustering regions are indicated by the black borders in each panel. Although not used in the clustering, shading shows the corresponding mean 12 h uncertainty growth rate LGRZ for Z250. Vectors are coloured blue when the humidity flux at 850 hPa exceeds 100 g kg−1 m s−1. More saturated shading, contours, vectors and dots indicate statistical significance at the 5 % level (not accounting for autocorrelation due to the discontinuous nature of date/times in each cluster).
To identify cyclone events further downstream in the storm track, a second clustering region is displaced north-eastward to [65–35∘ W, 35–55∘ N]. This region also contains 11 × 7 data points. Clustering results for this region are shown in Fig. 6 (bottom row). Cluster 1 (Fig. 6d, 62 date/times) highlights further cyclogenesis with a closed cluster-mean circulation at 850 hPa over Newfoundland and with strong growth rates, and (not shown) a mean drop in PMSL of 9 hPa. Note that, as might be expected, 44 of these 62 date/times (71 %) were in cluster 2 for region 1 (Fig. 6b).
Further east, towards the end of the storm track, processes get more variable. There can be propagation of cyclones from upstream at different latitudes, the formation of secondary cyclones along fronts, and the formation of cutoff lows, for example. This makes it more difficult to meaningfully cluster this region into cyclogenesis and non-cyclogenesis cases.
By combining the two cyclogenesis clusters over the western North Atlantic (Fig. 6a and d), a total of 91 date/times were identified as cyclogenesis flow types (32+62 minus 3 duplicates). For each of these date/times (and their counterpart date/times), visual inspection of plots similar to those in Fig. 1 suggests that the objective clustering has been successful in partitioning the date/times into cyclogenesis and non-cyclogenesis flow types. This then allows the evaluation of the extended error–spread budget for a large set of cyclogenesis events and of the counterpart set.
4.3 Forecast reliability during cyclogenesis in the ECMWF ensemble
Because Fig. 6a and d show partially evolved cyclogenesis flow types, it is necessary to wind-back the date/times a little to evaluate the day-2 extended error–spread budget during cyclogenesis. Winding back by one and two days gives very similar results (not shown). Also, conclusions are very similar for the evaluation based on the date/times obtained for the first region alone, albeit with the impact more confined to the western end of the storm track. Here, results are shown for a 2-day wind-back (consistent with the time for moderate deepening of a low-pressure system; Wernli and Davies, 1997) and for both regions together. This means that the cyclogenesis and counterpart composites represent a 91:89 partition (nearly 50:50) of the data used in Fig. 5 (top row).
Figure 7 shows the (square roots of) the terms in the extended error–spread equation Eq. (1) for Z250 at day 2 in the ECMWF ensemble, separately for cyclogenesis (top) and counterpart (middle) composites and their difference (bottom). The black border indicates the union of the two clustering regions. Comparison shows that ensemble spread for the cyclogenesis composite (Fig. 7b) is enhanced in the western part of the North Atlantic, while the spread for the counterpart composite (Fig. 7g) is centred more downstream. There are also corresponding differences in analysis uncertainty (Fig. 7c and h), possibly due to differing uncertainty growth rates in the background forecasts used within the ensemble data assimilation process.
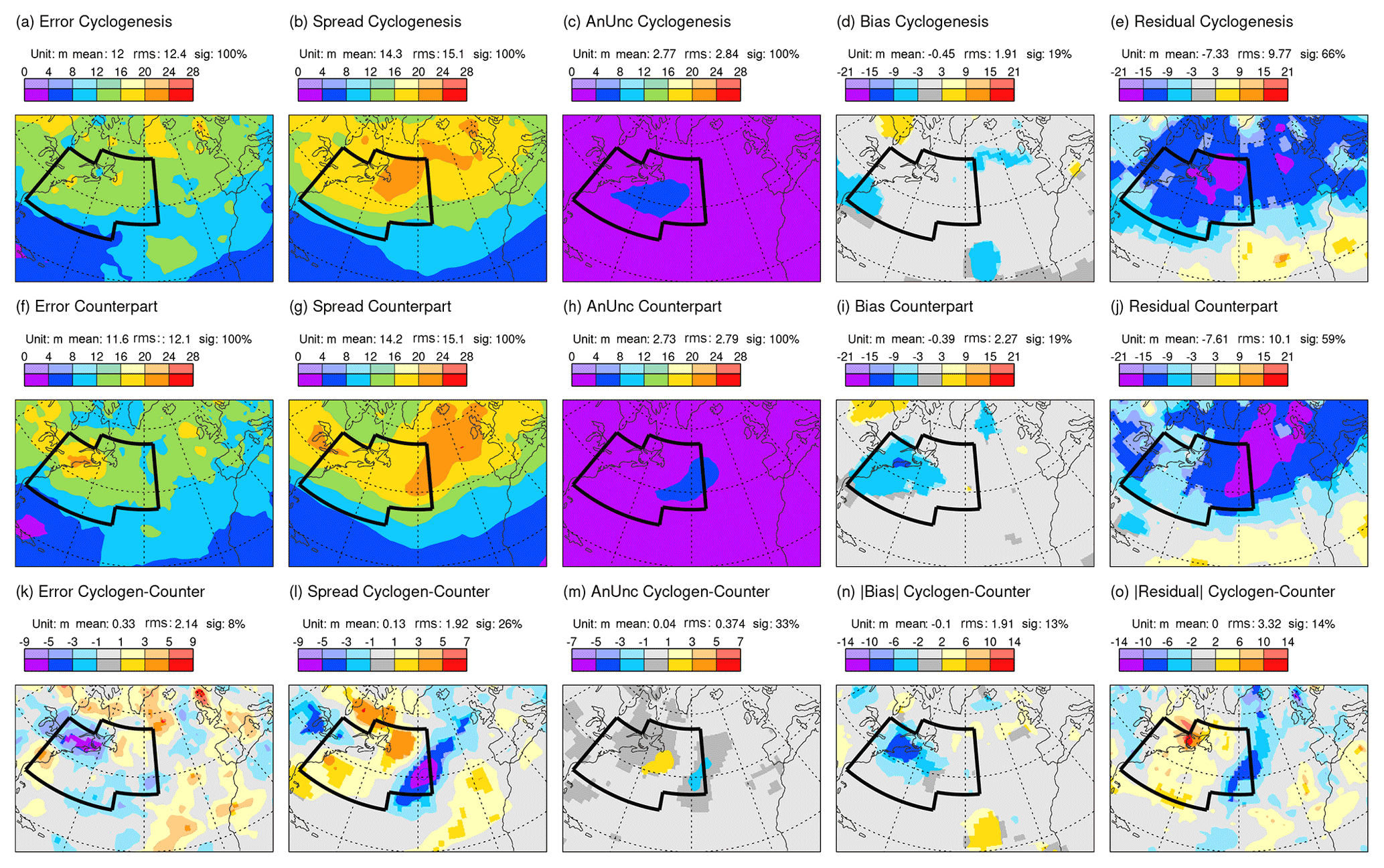
Figure 7As Fig. 5 but separately for the cyclogenesis composite date/times (top) and the non-cyclogenesis counterpart composite date/times (middle), for forecasts that start two days prior to the cluster classifications. The bottom row shows cyclogenesis minus counterpart. Note that differences in absolute bias and residual are shown, so that blue (red) colours anywhere on the bottom row show where results for the cyclogenesis composite are better (worse) than for the counterpart. The union of the two clustering regions is indicated by the black border.
Figure 7n indicates a significant flow-dependent difference in absolute forecast bias (of about 6 m) along the east coast of North America. This equates to a variance in forecast bias of ∼32 m2 – suggesting that this term is as important in (the residual term of) the day-2 extended error–spread budget for the whole of DJF 2020/2021 as the explicitly represented analysis uncertainty (Fig. 5c) and would suggest an even stronger over-spread issue (cf. term estimates in Sect. 4.1, with a revised reliable spread of ∼13.12 m2). In contrast, the positive residual term over the subtropical North Atlantic (Fig. 5e) could reflect variance in forecast bias (implied in Fig. 7n) rather than simply indicating ensemble under-spread. Here, in this flow-dependent evaluation, the forecast bias is explicitly represented for each composite in Fig. 7d and i. Notice that the stronger bias along the east coast of North America for the counterpart composite (cf. Fig. 7d and i) appears to account for the increased errors seen in this region (cf. Fig. 7a and f).
The overall assessment of ensemble spread is seen in the residual terms (Fig. 7e and j). Here it is evident for the ECMWF ensemble that most of the over-spread during DJF 2020/2021 in the western North Atlantic region of focus (Fig. 5e) is associated with the cyclogenesis composite – with statistically significant residuals in Fig. 7e and statistically insignificant residuals (indicated by the light blue and light grey colours) in Fig. 7j. Differences are shown in Fig. 7o. They are particularly strong and significant over Newfoundland (the 5 % significance level is a stringent test for a season's worth of data, which might be all that is available for evaluation of a new forecast system, and for a diffuse set of cyclogenesis events over the western North Atlantic). Downstream, both composites individually display negative residuals. This is consistent with the above discussion since there has been no direct control for downstream cyclogenesis. Indirectly, it is likely that occurrences of cyclogenesis events over the western North Atlantic are anticorrelated with the occurrences immediately downstream (as seen in cluster patterns Fig. 6c and e), and this might explain the negative cluster differences in absolute residual for the downstream region (Fig. 7o).
Linking the day-2 storm track over-spread (in the region of focus) to cyclogenesis is a key conclusion of this study. It does appear, therefore, that ECMWF initial ENS growth rates (Fig. 3a) associated with cyclogenesis events are too strong. This issue could be associated with several different aspects of the forecast system. Through sensitivity experiments, Sect. 5 explores some of the potential causes.
In Sect. 3, the initial growth rate of uncertainty (Eq. 3) was discussed. It has subsequently been demonstrated that these growth rates are likely to be too strong in the ECMWF ensemble during cases of extratropical cyclogenesis. Here, sensitivity experiments are used to investigate why this growth rate is too strong in the ECMWF ensemble during cyclogenesis, leading to over-spread at day 2.
Salient details of the ECMWF forecast system were presented in Sect. 2.1. Figure 8 shows the configuration of the sensitivity experiments. It refers to the base operational configuration as EDA = OP, ENS = OP. In the sensitivity experiments, this configuration is successively modified. Firstly, singular vector perturbations to the initial conditions of the ENS are turned off globally (OP-SV), and then model uncertainty in the ENS is turned off globally (OP-SV-MU). From this point, the parameterization of deep convection in the ENS is turned off in a local box (OP-SV-MU-DCP) or the ENS model horizontal grid resolution is increased to ∼4 km (OP-SV-MU + 4 km). Finally, the assimilation of observations in a local box is turned off for a single EDA cycle (OP-Obs), and the ENS is run again in the OP-SV-MU configuration. Differences between these configurations allow the diagnosis of individual aspects. Vertical arrows in Fig. 8 indicate the sign convention of the difference to be plotted (end of arrow minus beginning of arrow). The conclusions are not thought to be sensitive to the ordering of the various modifications. For example, it will be seen that the impacts on total precipitation of DCP and +4 km are small, and hence these impacts should be little changed in the presence of the SPPT form of MU. However, parameterized turbulent fluxes might be weakened with +4 km, and hence this impact could be somewhat different in the presence of MU.

Figure 8Configuration of IFS sensitivity experiments. These involve the Ensemble of Data Assimilations (EDA) and the ensemble forecast (ENS). Differences between these configurations allow the diagnosis of sensitivity to individual aspects as indicated. See main text for further details.
Figure 9 shows day-2 results for the standard deviation (spread) in Z250 from sensitivity experiments for the cyclogenesis case initialized at 12:00 UTC on 28 November 2019 (i.e. the validity time is one day later than that where the growth rate fields were centred in Figs. 2 and 3a in order to see the combined effect of the uncertainty source and the growth rate). Grey contours show PMSL, and the black contour shows the 2 PVU tropopause on 315 K in the unperturbed EDA analysis. A parallel set of results for spread in P315 is shown in Fig. 10. Note that shading intervals vary over the panels shown in these two figures, so that the structures of all impacts can be seen. Mean values and rms values, integrated over the area shown, are indicated above each panel.
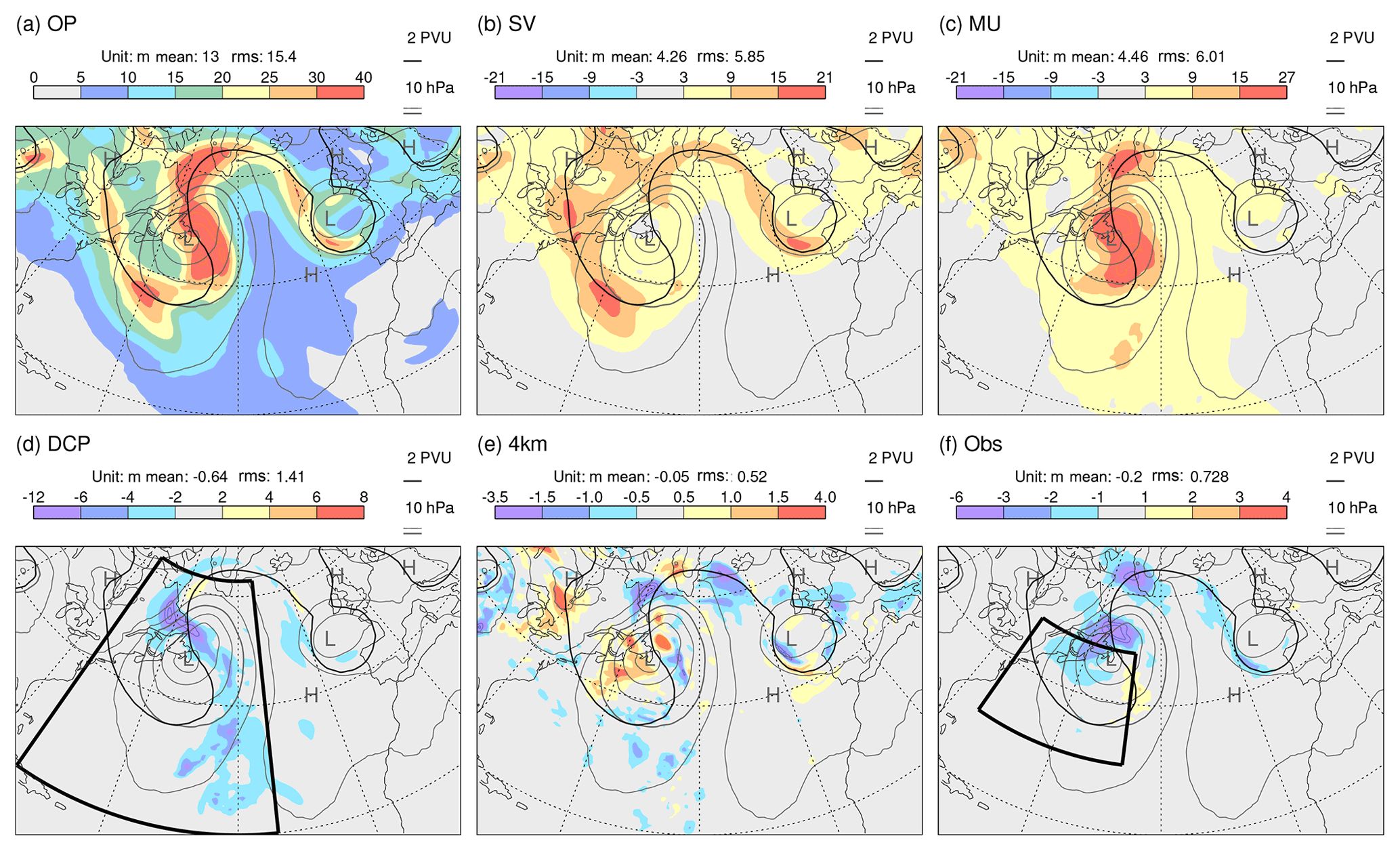
Figure 9Sensitivity results showing day-2 Z250 spread (shaded) from ECMWF ensemble forecast experiments initialized at 12:00 UTC on 28 November 2019. (a) Total spread for the near-operational configuration OP. (b–f) Differences in spread between experiments which highlight the impacts of (b) including initial singular vector perturbations, (c) including the model uncertainty representation, (d) including the parameterization of deep convection in the indicated region [75–34∘ W, 20–63∘ N], (e) an increase in model grid resolution to ∼4 km, and (f) the assimilation of observations in the indicated region [75–47∘W, 30–49∘ N]. Note that the shading interval varies across the panels. Contours extend the shading scheme, with the same interval. In these cases, the most extreme values are indicated at the ends of the colour bar. Mean values and rms values, integrated over the area shown, are indicated above each panel. Also shown in each panel are the PMSL (grey contours, with interval 10 hPa and the 1000 hPa contour shown more thickly) and PV = 2 PVU on the 315 K isentrope (black contour) from the unperturbed EDA analysis.
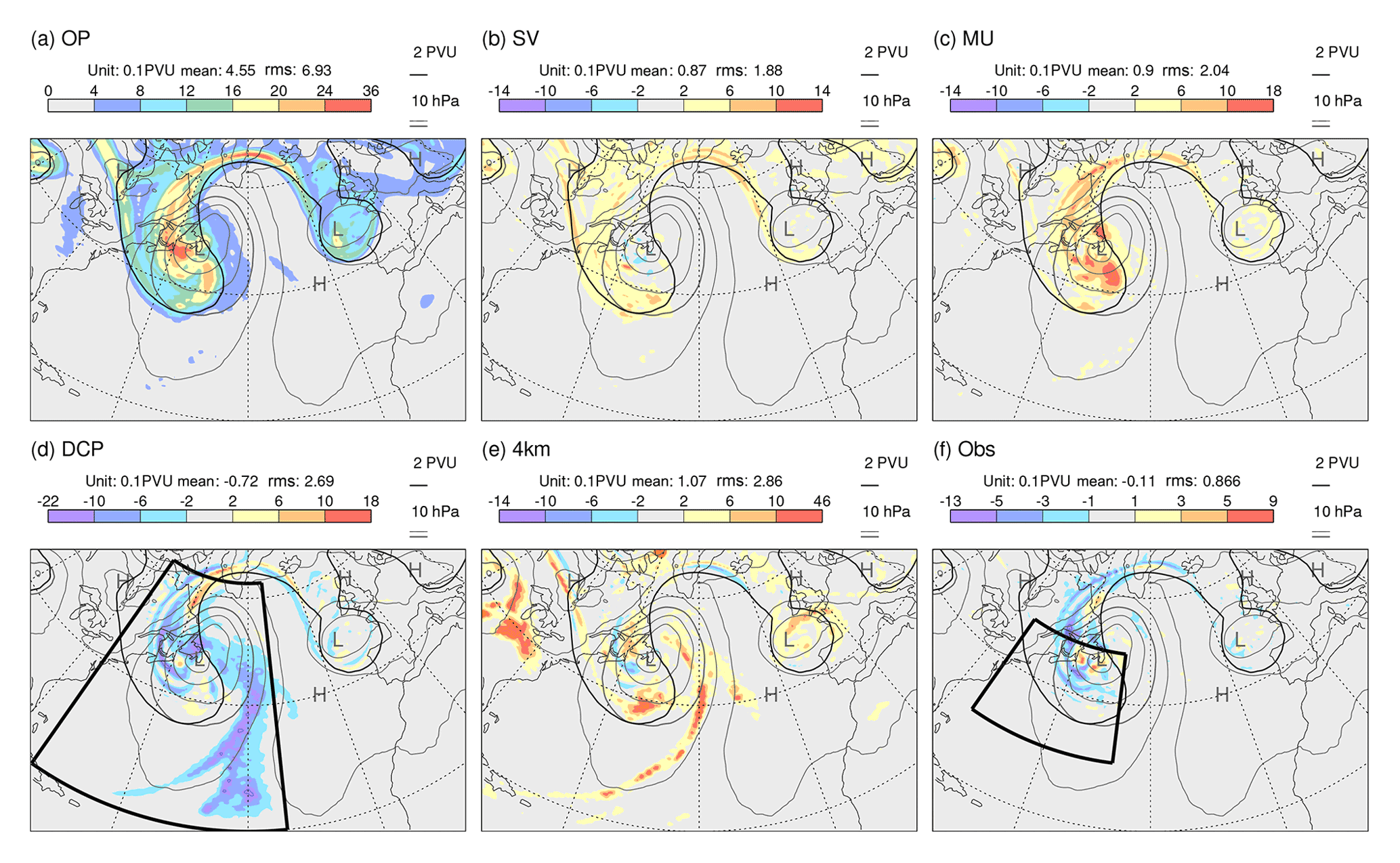
Figure 10As Fig. 9, but shading shows the spread in P315.
Figure 9a shows the OP configuration with a well-developed surface low pressure system, as discussed in relation to Fig. 1. The WCB associated with this cyclone is seen to lead to the development of a prominent downstream upper-level ridge and a trough west of Europe. As might be expected, the maximum Z250 spread is located downstream of the maximum Lagrangian growth rates (cf. Fig. 3a).
The impact of the initial singular vector perturbations on Z250 spread (Fig. 9b) is particularly pronounced along the western flank of the trough over the western North Atlantic (and also of the trough west of Europe). This likely indicates the potential for dynamic growth along the intense jets in these regions, qualitatively in line with the idealized studies by Hakim (2000). This singular vector impact might help explain the apparent slight westward shift of the centre of maximum growth in the ENS (Fig. 3a) relative to the EDA (Fig. 2). There are places where the singular vector impact on spread is half the total (so that the fraction of variance explained reaches 25 %). In contrast to the singular vector impact, the impact of the model uncertainty representation (Fig. 9c) is particularly pronounced in the cyclone centre and in the region of the WCB ahead of the surface low, i.e. in regions where cloud-related physical processes are particularly active. The large signal along the western flank of the ridge southwest of Greenland is consistent with the results of Joos and Forbes (2016), who found a large influence of cloud microphysical processes in the WCB on the tropopause structure in this part of the downstream ridge. Model uncertainty also explains up to 25 % of the total variance. The remaining variance must be associated with the growth of initial EDA analysis uncertainty. This suggests that, even without singular vectors and model uncertainty, this cyclogenesis event acts as a strong magnifier of the initial uncertainty.
Figure 9d shows the impact of including the deep convection parameterization (DCP) in the indicated region (note the smaller contour interval). There is a reduction in the spread, particularly in the WCB region, compared to when the model is forced to represent this convection on its 16 km grid. Interestingly ensemble mean total precipitation (parameterized plus resolved) is little changed when turning off parameterized deep convection, both in location and amount (not shown).
The impact of increasing the model grid resolution to ∼4 km is mixed. For Z250 spread (Fig. 9e; note the smaller contour interval), the impact is generally weak. In contrast the impact on P315 spread (Fig. 10e) is strong, particularly within the WCB region. At 4 km, the model attempts to resolve more of the convection. The resolved convection can be associated with stronger updraughts, which might perturb the tropopause more vigorously, where PV gradients are particularly strong. Given that model uncertainty representation is thought to partly account for the impact of sub-grid-scale uncertainty, perhaps the most interesting aspect here is the lack of agreement with the model uncertainty impact (cf. Fig. 10e and c). The impact on P315 uncertainty of allowing the model to resolve more of the convection at the 4 km resolution (Fig. 10e) appears to be in closer agreement with that when forcing the model to represent the convection on the 16 km grid (minus Fig. 10d). The increase in resolution also results in a small shift of ensemble mean precipitation from parameterized to resolved, with little change in the total (not shown).
The impact of assimilating local observations is obtained using an EDA experiment (OP-Obs; see Fig. 8) where all observations were denied to the EDA in the region [75–47∘ W, 30–49∘ N] for the single 12 h data assimilation window that generated the initial conditions; observations outside this region are used in both EDA = OP and EDA = OP-Obs. It is not so easy to anticipate the impact of local observations, particularly with 4DVar, when remote observational information can propagate into the region. Results demonstrate that the assimilation of observations in this baroclinic region does reduce initial uncertainty (not shown). Figures 9f and 10f show the impact at day 2 (note the smaller contour intervals compared to those for the singular vector and model uncertainty impacts). There is a reduction in spread in the developing low, which suggests that the assimilation of local observations is beneficial in this case.
Very similar results to those above were obtained for a second set of experiments initialized at 00:00 UTC on 17 January 2020 – indicating that the conclusions about ensemble spread sensitivity (based on 50 members) may be robust even with only two cases (the same could not be said for error sensitivity with just two cases). In particular, the singular vector impact is largely along the western flank of the trough, and the model uncertainty impact is in the region of the WCB. Again, the parameterization of deep convection acts to reduce spread in the WCB. For P315, the impact of increased resolution is again more similar to the effect of turning off the deep convective parameterization than to that of model uncertainty. The main difference of note is that, while there is a reduction in initial spread from the assimilation of local observations, it is weaker than in the case shown above, and its impact at day 2 is marginal.
The above results suggest that singular vectors, model uncertainty, and the deterministic model itself all play important roles in the early development of operational ensemble spread during cyclogenesis. (This is true globally, as can be seen in the variance spectra in Fig. C1 in Appendix C.) Since the motivation for the use of singular vector perturbations (Magnusson et al., 2009) and the initial reason for the development of model uncertainty representations (Buizza et al., 1999) was to increase ensemble spread, it makes sense to investigate how these techniques might be modified to reduce the growth of spread during cyclogenesis without negatively impacting the overall performance of the ensemble.
The goal of probabilistic forecasting is to maximize the sharpness of the predictive distributions subject to reliability (Gneiting and Raftery, 2007). In ensemble forecasting, better sharpness is associated with reduced ensemble variance, and reliability is associated with the mean agreement between ensemble and outcome distributions. As argued by Rodwell et al. (2018), a focus on short-range flow-dependent reliability (and reduced initial uncertainty) may represent a practical path towards this goal. Synoptic scales are particularly important in global numerical weather prediction because these are the scales that contribute most to ensemble variance over the first few days (Tribbia and Baumhefner, 2004; see, also, Fig. C1 in Appendix C). It is important to understand what processes drive this growth and how well reliability is maintained.
Here, a “Lagrangian growth rate” diagnostic LGRP, on the first line in Eq. (3), has been calculated for 12 h forecasts of upper-tropospheric potential vorticity P315 in the background ensemble of the ECMWF Ensemble of Data Assimilations (EDA). The supplementary animation of LGRP for the DJF 2020/2021 season highlights a few flow situations over the North American–North Atlantic–European region where ensemble variance growth at synoptic scales is particularly strong and concentrated. Note that this concentration of growth rates is not dependent on singular vectors perturbations, since these perturbations are not included in the EDA. One such situation is associated with the deepening of extratropical cyclones (cyclogenesis). The material growth identified by LGRP has two source terms, on the second line in Eq. (3). In situations of cyclogenesis, it is speculated here that uncertainties in baroclinic growth (Hoskins et al., 1985) might be important for enhancing variance growth at the southern extent of upper-tropospheric troughs (Fig. 2). Uncertainties in the erosion of the leading edge of the upper-tropospheric PV anomaly by latent heating (Ahmadi-Givi et al., 2004) may be acting to weakly decrease variance in the downstream ridge building region. However, Baumgart and Riemer (2019) suggested that the strongest contribution to ensemble variance is associated with local dynamical interactions between upper-tropospheric PV deviations and the winds that they induce. One issue is how to diagnose sources of ensemble variance growth in the face of considerable redistribution of existing variance. A better understanding of the dominant processes involved could help motivate modelling developments and help data assimilation efforts focus on initializing the most important fields.
The multi-model TIGGE archive (Swinbank et al., 2016) has been used to calculate Lagrangian growth rates in 12 h forecasts of upper-tropospheric geopotential heights Z250 for several ensemble systems. Results (Figs. 3 and 4) suggest high sensitivity of the growth rate to initialization and/or modelling aspects (Table 1). Based on the animations available in the Supplement, all models show a general enhancement of growth rates in cyclogenesis situations, although often not to the same extent seen in the ECMWF system. Does background continuity within a given EDA member, from one analysis cycle to the next, facilitate the growth of differences (e.g. in baroclinic structures) between EDA members? Does this suggest that singular vector perturbations, applied during the initialization of the medium-range ensemble forecast, are less needed following the introduction of the EDA? More generally, a better understanding of the differences in initial growth rates between TIGGE models would be useful. For example, what are there sensitivities to the deterministic models (Magnusson et al., 2022), to the representations of model uncertainty, and to the structures represented in the initial uncertainty?
The reliability of each TIGGE ensemble system was evaluated over the DJF 2020/2021 season by assessing the consistency between day-2 forecast error and spread in Z250. This was done taking into account bias and uncertainty in the verifying analyses through use of the extended error–spread Eq. (1). The ECMWF ensemble displays the smallest error, analysis uncertainty, and bias (Fig. 5 columns 1, 3, 4) in the North Atlantic storm track, but it is over-spread (Fig. 5e). The UK Met Office ensemble showed the best reliability (Fig. 5 column 5). There is some consistency, therefore, between the Lagrangian growth rate results and the reliability evaluation. The conclusions on reliability appear to extend to other parameters (such as geopotential heights and temperatures at 500 hPa), other seasons, and other storm tracks and continue until the most recent check for the March–May season 2022 (not shown). We would argue that balance in the extended error–spread equation provides a superior reliability target for system development. For example, in the ECMWF ensemble, the standard deviation in day-2 Z250 over the east coast of North America during DJF 2020/2021 was 18 m. The standard error–spread equation suggests a target of 15 m, while the extended error–spread equation suggests a target of 13.4 m. Including an estimate of the variance of forecast bias reduces this target further to 13.1 m. Moreover, at short forecast ranges, the extended equation can provide a better target for improvements in flow-dependent reliability.
Clustering on flow types in the western part of the North Atlantic storm track (Fig. 6) demonstrated that the ECMWF over-spread in this region is associated with cyclogenesis events (Fig. 7). Sensitivity studies (Fig. 8) with the ECMWF ensemble reveal some information on the sources of uncertainty during cyclogenesis (Figs. 9 and 10). A large part is associated with the chaotic growth of the initial (EDA) uncertainty in the deterministic model. Singular vector perturbations to the initial conditions and the model uncertainty representation are also important for the day-2 spread. We speculate here that, when other factors permit, a reduction in the magnitude of the dry singular vector perturbations could improve both sharpness and reliability within the storm track regions and make the ensemble forecast more consistent over lead times (more seamless). This would then permit a better use of initial growth rates in the evaluation and improvement of the model and model uncertainty – something that would be beneficial throughout the forecast range.
Sensitivities to switching off the parameterization of deep convection and to increasing model resolution (see, also, Wedi et al., 2020) suggest that the model uncertainty representation should be more strongly focused on convective instabilities (e.g. Christensen et al., 2017). It is possible that such a focus on instabilities (rather than the effects of already-triggered instabilities) might be better explored within the future “stochastically perturbed parameter” (SPP) framework for model uncertainty – perturbing triggering thresholds for example.
In addition to cyclogenesis situations, initial growth rates tend to support the idea that uncertainty can be concentrated in other flow situations, including those prone to mesoscale convection over North America (Palmer et al., 2014) and during the extratropical transition of tropical cyclones. Similar investigations of these initial growth rates could also lead to better flow-dependent reliability and improved overall forecast performance.
Figure A1 shows the key concepts involved in the evaluation of ensemble error–spread reliability. For clarity, the figure is shown in two dimensions and could relate, for example, to the prediction of the location of a storm. For a reliable forecast system (Hamill, 2001; Saetra et al., 2004), the verifying truth T should be statistically indistinguishable from any random sampling of the forecast distribution F, indicated by the grey concentric circles. This distribution, which need not be Gaussian or even unimodal, has mean μF and standard deviation of distances from the mean σF (dashed grey line). Introducing a suffix j to indicate the forecast initiated at time tj with then, since Fj is reliable (and assumed to be the only information available at time tj about Tj), the expectation 𝔼j[⋅] at time tj is that 𝔼j[Tj]=μFj and . The latter condition means that, in Fig. A1, the expected squared length of the top blue line should match the squared length of the dashed grey line. This leads to the well-known error–spread relation in ensemble forecasting – that reliability requires , where and are the mean and standard deviation estimators, respectively, based on m ensemble members, and the overline here indicates a mean over the n forecasts. Equality here can be improved by accounting for the finiteness of m and increasing n (Leutbecher and Palmer, 2008). However, for the short forecast lead times of interest here, the error–spread relation is not adequate in general. This is because uncertainties in the knowledge of the verifying truth can be non-negligible compared to forecast variances at short lead times. Below, Appendix A1 gives a derivation of an extended error–spread equation, which accounts for bias, analysis uncertainty, and sampling. The components of the “residual”, which closes the budget, are discussed further in Appendix A2.
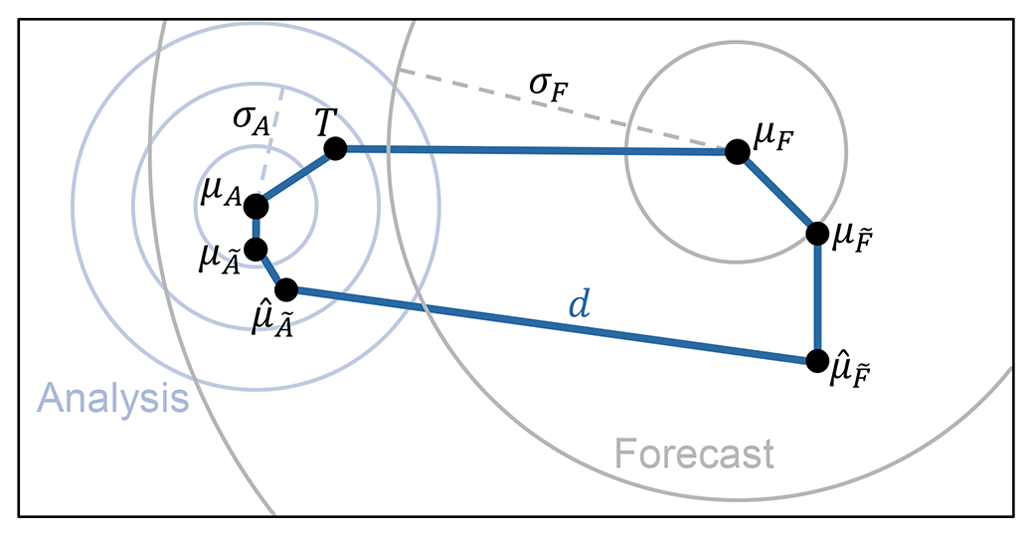
Figure A1Key concepts in the evaluation of ensemble error–spread reliability. The departure d is the difference between the ensemble mean of the forecast and the ensemble mean of the verifying analysis . The forecast and analysis ensembles can be considered as finite samplings of underlying distributions with (mean,variance) and , respectively. Circles depict the hypothetical forecast and analysis distributions with (mean,variance) and , respectively, that would be created with a perfect model (but with imperfect/incomplete observational information). The truth is indicated by a T. See the main text for further discussion.
A1 Derivation of the extended error–spread equation
The extended error–spread equation takes account of analysis uncertainty. A reliable analysis distribution A, which is consistent with the indicated truth T, is shown in Fig. A1 using blue concentric circles, with mean μA and standard deviation of distances from the mean σA (dashed blue line). Let and be underlying distributions associated with an unreliable forecast system. These distributions could be biased – their means and , respectively, are shown offset from those of the reliable distributions. The ensemble means, based on samplings of these distributions, are indicated by and . These latter two parameters, along with their difference (or departure) d, are the only parameters shown in Fig. A1 that are available, being obtained from the ensemble forecast system. Perhaps more importantly for reliability, the distributions and could have deficiencies in their variances and , respectively. Are they under-spread or over-spread with respect to the variances of the reliable distributions, for example? Again, it is only the ensemble sample estimators and that are available.
For initial time tj, the departure of the ensemble mean forecast from the ensemble mean analysis can be written (by following the other solid blue lines in Fig. A1) as
where the last line is just a convenient re-arrangement of the terms on the second line.
Although only dj, , and are quantifiable, it is possible to discuss the expected values of the terms 1–6 in Eq. (A1). The expectation operator 𝔼j[⋅], introduced above, is the expectation for a given initial time tj. The forecast distributions Fj and are fixed for given initial time, so the expectation 𝔼j is over the potential Tj (with distribution Fj) and the potential analysis distributions Aj and (which are dependent on Tj). The expectation is also over the finite ensemble samplings of and of . The reliability of Aj(Tj) implies that and . Taking the expectation of the last line in Eq. (A1) we have
since terms 1–4 in Eq. (A1) have zero expectation. Hence 𝔼j[dj]=βj : the expected bias of the unreliable forecast minus the expected bias of the unreliable analysis . As lead time increases, one might expect that the forecast bias will become the dominant component of βj.
The extended error–spread equation is based on the expected square of Eq. (A1). This involves squared terms, such as 𝔼j[1⋅1], and cross terms, such as 2𝔼j[1⋅6]. With the squared terms presented in the same order as in the last line in Eq. (A1) the expected square of Eq. (A1) can be written as
The term in braces { } comprises the “variance deficit” (which compares the reliable and unreliable variances of the ensemble forecast and analysis) and ℰj, which collects any potentially non-zero cross terms and the (expected) variance in analysis bias (discussed further in Appendix A2).
From Eq. (A3), the expected squared departure (over an infinite set of initial forecast times tj) can then be written as
with expected residual:
where the variance in forecast bias accounts for the explicit replacement of 𝔼[β2] with 𝔼[β]2 in Eq. (A4). It can be seen that all terms that involve variations in bias have been moved into the residual.
For an unbiased estimator of Eq. (A4), we note that , which has unbiased estimator , and obtain the extended error–spread equation:
where the various terms have been named for future reference. For the purposes of calculating statistical significance, is written as the mean of the residuals Rj:
which close the budget for each initial time (for given constant ). The extent to which is a good estimate for the expected variance deficit in Eq. (A5) will depend on the magnitude of the other terms in Eq. (A5). This is investigated in Appendix A2. It is suggested that the main term which could be non-negligible is the variance in forecast bias, .
A2 Estimating contributions to the residual term
It is not trivial to estimate the contributions to the residual(2) term in Eq. (A6), but a rough attempt is made here. It is useful to write (= minus term 6 in Eq. A1) for the bias in the verifying analysis distribution associated with a given realization of the truth and subsequent assimilation of observations. Then, from Eq. (A2), the expected bias in the verifying analysis is given by .
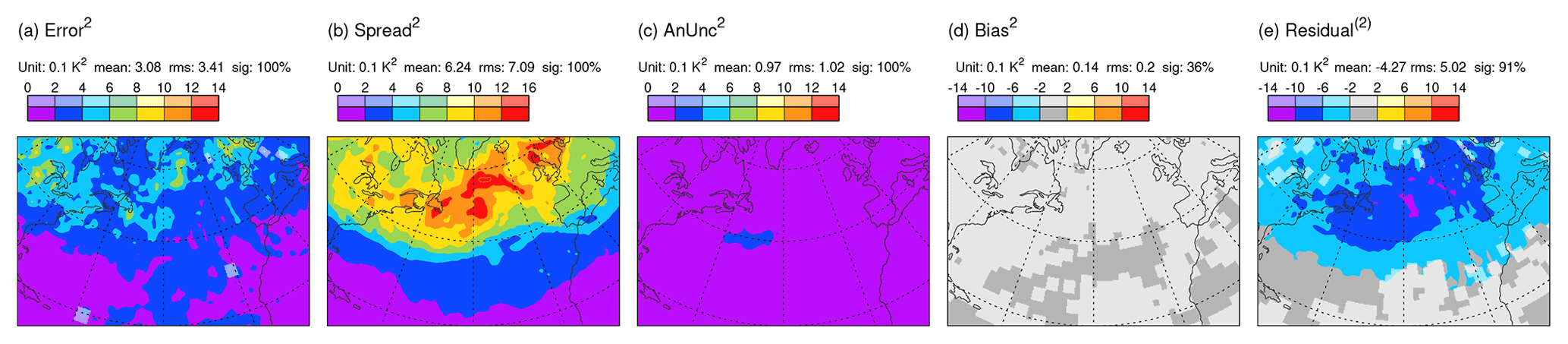
Figure A2Extended error–spread budget (squared terms) for DJF 2020/2021 for T500 on day 2 from ECMWF ensemble forecasts. Statistically significant values are shown with more saturated colours. Area means (for the area displayed) are indicated at the top of each panel (e.g. “sig: 85 %” means that 85 % of the area is significant at the 5 % significance level).
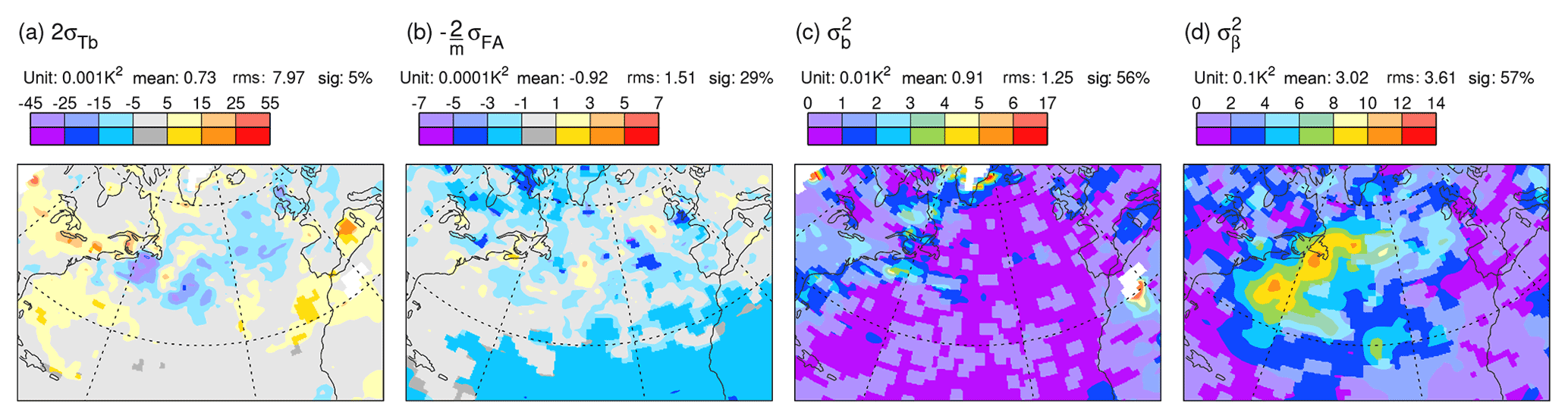
Figure A3Estimates of the magnitudes of the other terms included in the residual for T500 during the period DJF 2020/2021. (a) Covariance of the analysis bias with the atmospheric state (×2). (b) Covariance of the ensemble-mean day-2 forecast and ensemble-mean analysis (). (c) Variance of the analysis bias. (d) Variance of the day-2 forecast bias (relative to analysis). Note that the units differ widely between panels. Statistically significant values are shown with more saturated colours. Area means (for the area displayed) are indicated at the top of each panel (e.g. “sig: 29 %” means that 29 % of the area is significant at the 5 % significance level). Please see main text for further details.
With reference to the numbered terms in Eq. (A1), one potential cross term contained in ℰj of Eq. (A3) is . The covariance , when divided by , measures the linear dependence of the analysis bias on the truth, and this could be non-zero. In the ECMWF EDA, each analysis member is an innovation of that member's background forecast, and this lack of independence might imply that the cross term is non-zero, particularly at very short lead times and for small ensemble size m. (Note that the division by m here is because the covariance of ensemble means is being estimated by the covariance of the two distributions.) With sufficient observational information, all other cross terms are likely to have zero expectation with the exception of , which is explicitly represented in the term in Eq. (A3). Finally note that , and so ℰj should also include , the (expected) variance of the analysis bias. Hence
The expected residual in Eq. (A5) can then be written as
As noted in the main text, all terms that involve variations in bias have been moved into the residual. Here, an attempt is made to estimate these terms for day-2 forecasts of T500 during the December–February (DJF) season. Mid-tropospheric temperatures are chosen here because they are relatable, through vertical integration of the hydrostatic equation, to the upper-tropospheric height field discussed in the main text and because relevant temperature observations are assimilated into the EDA. Here, “AMSUA” channel-5 satellite brightness temperature observations are used. These measure mid-tropospheric temperatures with a maximum weighting at ∼500 hPa and have had variational bias correction, VarBC, applied. For reference, Fig. A2 shows the terms of the extended error–spread Eq. (A6) in squared units. Consistent with the upper-tropospheric height field results in the main text, this also highlights a potential over-spread in the storm track. The following list outlines the approach taken here to estimate four terms on the second line of Eq. (A9).
-
2𝔼[σTb] in Eq. (A9) is tricky to estimate as it requires the state-dependent estimation of analysis bias. One approach is to utilize inter-annual variability over the ny (= 10) years 2012–2021 and to regress the DJF-mean analysis bias (relative to a set of observations) against the DJF-mean observations themselves. The so-called “analysis departure” is the observation minus the analysis-equivalent of the observation (after applying the relevant observation operator). Assuming that the analysis bias (here for T500) closely matches minus the mean analysis departure from the AMSUA brightness observations, we can make the estimate
where o refers to the seasonal means of the observations, and a refers to the seasonal means of the analyses. Notice that the bias variations are scaled to reflect the synoptic variations in truth during DJF 2020/2021. Figure A3a shows that, over the North Atlantic, this estimated covariance is ∼0.025 K2. This is generally smaller in magnitude than the analysis variance ∼0.2 K2 (Fig. A2c) and clearly smaller in magnitude than the full residual ∼0.6 K2 (Fig. A2e).
-
in Eq. (A9) can also be estimated by utilizing inter-annual variability of seasonal means:
where the multiplier n′ is the number of synoptic degrees of freedom in a season (here assuming a 3 d synoptic decorrelation timescale). Figure A3c shows that this term is ∼0.02 K2 in the North Atlantic region, so again smaller than the analysis variance and residual terms.
-
in Eq. (A9) can be estimated by trying a similar approach:
where f refers to the day-2 seasonal means of the (deterministic HRES) forecasts. Figure A3d shows that this term is ∼1 K2 over the western North Atlantic region. This may be an over-estimate since reducing predictive skill with lead time means that (f−a) begins to reflect (minus) the observed anomaly from climate and thus becomes less useful at indicating forecast bias as the forecast lead time increases (e.g. by day 10). There is also some uncertainty in the value chosen for n′. Nevertheless, variations in forecast bias may well provide a non-negligible contribution to the residual term – implying here that the over-spread is even larger over the western North Atlantic. Flow-dependent evaluation of the extended error–spread budget, discussed in Sect. 4.3, represents a means of reducing issues associated with flow-dependent variations in forecast bias.
-
in Eq. (A9) does not involve bias and can be estimated in-sample as
The scale to the colour bar in Fig. A3b shows that this term is several orders of magnitude smaller than the analysis variance and residual terms.
Considering all these terms, it appears that the residual in the day-2 T500 budget largely represents the ensemble variance deficit and, possibly, the variance in forecast bias – which is appreciable in the cyclogenesis region off the east coast of North America. With the relationship between mid-tropospheric temperatures and upper-tropospheric heights discussed above, it is thought that this conclusion will carry over to the upper-tropospheric height field budget discussed in the main text.
For any parameter Y, write Yi for its value in ensemble forecast member . Using an overline here to denote a mean over ensemble members (even for non-linear terms: ) and a prime to denote deviations from the mean , the variance estimator for potential vorticity P can be written as . Using this notation and the results that and , the local exponential growth rate for P can be written as
The first term on the last line is the advection of uncertainty by the ensemble mean wind. Equation (B1) can be rearranged to give Eq. (3).
Figure C1 shows the T500 variance spectra of global spherical harmonics against total wavenumber for the experiments discussed in Sect. 5. The approximate scale is indicated on the top x axis. Initial uncertainty from the EDA (Fig. C1, thin green curve) occurs at all scales, with the largest variance contributions at scales ∼400 km. The thin black curve shows the initial spectrum after addition of the singular vector perturbations (at scales ⩾1000 km). The contributions to day-2 variance associated with singular vector perturbations and model uncertainty representation are indicated by the red and green shaded regions, respectively. Singular vectors contribute strongly at synoptic scales, while model uncertainty contributes at synoptic and planetary scales. The thick green curve indicates the impact of pure chaotic growth of EDA uncertainty without singular vectors or model uncertainty in the forecast. Notice that the day-2 and EDA variance spectra coincide at scales smaller than ∼100 km – indicating that the EDA variance is already saturated at these scales. The thick blue curve shows the day-2 spectrum when the grid-point resolution of the forecast model is increased to ∼4 km. The spectrum is seen to shallow, even at scales already represented by the original ∼16 km model (as indicated by the blue shaded region). A similar plot based on the same set of experiments for the second initial date (00:00 UTC on 17 January 2020) is almost indistinguishable from Fig. C1.
Figure C1Spectra of ensemble T500 variance for the indicated experiments, summarized in Fig. 8. Spectra show the variance of the ensemble filtered on total wavenumber n for global spherical harmonics. The approximate scale of each harmonic is indicated on the top x axis (this relates to a half wavelength assuming equal zonal and meridional wavenumbers). Thin lines show initial time, and thick lines show day 2. The red, green, and blue shaded regions indicate the impacts at day 2 of including initial singular vector (SV) perturbations, model uncertainty (MU) representation, and increasing the grid-point resolution of the forecast model to ∼4 km, respectively. Diagonal dotted lines are contours of variance contribution per linear unit length on the x axis, with contour value proportional to the y intercept. Total variance for each experiment is indicated in parentheses in the key.
The key conclusions in this study are derived from data in the TIGGE archive (https://confluence.ecmwf.int/display/TIGGE, Bougeault et al., 2010), which is freely accessible. The ERA5 reanalysis data (https://doi.org/10.24381/cds.143582cf, Hersbach et al., 2017) are also freely available. Other data and diagnostic code are available from the authors upon request.
Growth rate animations are available at https://doi.org/10.3929/ethz-b-000605102 (Rodwell and Wernli, 2023).
This study arose from close collaboration between the authors during HW's period as an ECMWF Fellow, and from ideas generated in the Warm Conveyor Belt workshop, which they co-organized in 2020. The mathematical content and much of the diagnostic work for this study was completed by MJR, with HW providing important guidance throughout.
At least one of the (co-)authors is a member of the editorial board of Weather and Climate Dynamics. The peer-review process was guided by an independent editor, and the authors also have no other competing interests to declare.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
For the sensitivity experiments, the authors would like to thank Peter Bechtold, Andrew Dawson, Richard Forbes, Alan Geer, Elias Hólm, Bruce Ingleby, Simon Lang, Inna Polichtchouk, and Gabor Radnoti for their considerable technical assistance. The authors would also like to thank Katharina Heitmann (ETH Zurich) for preparing Fig. 1 and Jonathan Day, Rebecca Emerton, David Lavers, Martin Leutbecher, Linus Magnusson, Florian Pappenberger, and David Richardson for useful discussions about this work. The authors express their great appreciation to Ron McTaggart-Cowan and an anonymous reviewer for their time and insightful remarks, which have led to improvements in the manuscript. Part of this work is based on TIGGE data. TIGGE (The International Grand Global Ensemble) is an initiative of the World Weather Research Programme (WWRP).
This paper was edited by Michael Riemer and reviewed by Ron McTaggart-Cowan and one anonymous referee.
Ahmadi-Givi, F., Graig, G. C., and Plant, R. S.: The dynamics of a midlatitude cyclone with very strong latent-heat release, Q. J. Roy. Meteor. Soc., 130, 295–323, https://doi.org/10.1256/qj.02.226, 2004. a, b
Baumgart, M. and Riemer, M.: Processes governing the amplification of ensemble spread in a medium-range forecast with large forecast uncertainty, Q. J. Roy. Meteor. Soc., 145, 3252–3270, https://doi.org/10.1002/qj.3617, 2019. a, b, c, d
Bechtold, P., Köhler, M., Jung, T., Doblas-Reyes, F., Leutbecher, M., Rodwell, M. J., Vitart, F., and Balsamo, G.: Advances in simulating atmospheric variability with the ECMWF model: From synoptic to decadal time-scales, Q. J. Roy. Meteor. Soc., 134, 1337–1351, 2008. a
Bechtold, P., Semane, N., Lopez, P., Chaboureau, J., Beljaars, A., and Bormann, N.: Representing Equilibrium and Nonequilibrium Convection in Large-Scale Models, J. Atmos. Sci., 71, 734–753, https://doi.org/10.1175/JAS-D-13-0163.1, 2014. a
Bishop, C. H., Etherton, B. J., and Majumdar, S. J.: Adaptive Sampling with the Ensemble Transform Kalman Filter. Part I: Theoretical Aspects, Mon. Weather Rev., 129, 420–436, https://doi.org/10.1175/1520-0493(2001)129<0420:ASWTET>2.0.CO;2, 2001. a
Bonavita, M., Hólm, E., Isaksen, L., and Fisher, M.: The evolution of the ECMWF hybrid data assimilation system, Q. J. Roy. Meteor. Soc., 142, 287–303, https://doi.org/10.1002/qj.2652, 2016. a
Bougeault, P., Toth, Z., Bishop, C., Brown, B., Burridge, D., Chen, D. H., Ebert, B., Fuentes, M., Hamill, T. M., Mylne, K., Nicolau, J., Paccagnella, T., Park, Y.-Y., Parsons, D., Raoult, B., Schuster, D., Dias, P. S., Swinbank, R., Takeuchi, Y., Tennant, W., Wilson, L., and Worley, S.: The THORPEX Interactive Grand Global Ensemble, B. Am. Meteorol. Soc., 91, 1059–1072, https://doi.org/10.1175/2010BAMS2853.1, 2010 (data available at: https://confluence.ecmwf.int/display/TIGGE, last access: 4 July 2023). a, b, c
Buizza, R., Miller, M., and Palmer, T. N.: Stochastic representation of model uncertainties in the ECWMF Ensemble Prediction System, Q. J. Roy. Meteor. Soc., 125, 2887–2908, https://doi.org/10.1002/qj.49712556006, 1999. a, b, c
Christensen, H. M., Lock, S.-J., Moroz, I. M., and Palmer, T. N.: Introducing independent patterns into the Stochastically Perturbed Parametrization Tendencies (SPPT) scheme, Q. J. Roy. Meteor. Soc., 143, 2168–2181, https://doi.org/10.1002/qj.3075, 2017. a
Dee, D. P.: Variational bias correction of radiance data in the ECMWF system, in: ECMWF Workshop on Assimilation of High Spectral Resolution Sounders in NWP, ECMWF, Shinfield Park, Reading, Berkshire, UK, 97–112, 2004. a
Durran, D. R. and Gingrich, M.: Atmospheric Predictability: Why Butterflies Are Not of Practical Importance, J. Atmos. Sci., 71, 2476–2488, https://doi.org/10.1175/JAS-D-14-0007.1, 2014. a
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res., 99, 10143–10162, https://doi.org/10.1029/94JC00572, 1994. a
Geer, A. J., Lonitz, K., Weston, P., Kazumori, M., Okamoto, K., Zhu, Y., Liu, E. H., Collard, A., Bell, W., Migliorini, S., Chambon, P., Fourrié, N., Kim, M.-J., Köpken-Watts, C., and Schraff, C.: All-sky satellite data assimilation at operational weather forecasting centres, Q. J. Roy. Meteor. Soc., 144, 1191–1217, https://doi.org/10.1002/qj.3202, 2018. a
Gneiting, T. and Raftery, A. E.: Strictly Proper Scoring Rules, Prediction, and Estimation, J. Am. Stat. Assoc., 102, 359–378, https://doi.org/10.1198/016214506000001437, 2007. a, b
Grams, C. M. and Blumer, S. R.: European high-impact weather caused by the downstream response to the extratropical transition of North Atlantic Hurricane Katia (2011), Geophys. Res. Lett., 42, 8738–8748, https://doi.org/10.1002/2015GL066253, 2015. a
Grams, C. M., Magnusson, L., and Madonna, E.: An atmospheric dynamics perspective on the amplification and propagation of forecast error in numerical weather prediction models: A case study, Q. J. Roy. Meteor. Soc., 144, 2577–2591, https://doi.org/10.1002/qj.3353, 2018. a
Hakim, G. J.: Role of Nonmodal Growth and Nonlinearity in Cyclogenesis Initial-Value Problems, J. Atmos. Sci., 57, 2951–2967, https://doi.org/10.1175/1520-0469(2000)057<2951:RONGAN>2.0.CO;2, 2000. a
Hamill, T. M.: Interpretation of Rank Histograms for Verifying Ensemble Forecasts, Mon. Weather Rev., 129, 550–560, https://doi.org/10.1175/1520-0493(2001)129<0550:IORHFV>2.0.CO;2, 2001. a, b
Hartigan, J. A. and Wong, M. A.: Algorithm AS136: A K-means clustering algorithm, J. R. Stat. Soc. C.-Appl., 28, 100–108, 1979. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz‐Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: Complete ERA5 from 1940: Fifth generation of ECMWF atmospheric reanalyses of the global climate, Copernicus Climate Change Service (C3S) Data Store (CDS) [data set], https://doi.org/10.24381/cds.143582cf, 2017. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020. a
Hirons, L. C., Inness, P., Vitart, F., and Bechtold, P.: Understanding advances in the simulation of intraseasonal variability in the ECMWF model. Part I: The representation of the MJO, Q. J. Roy. Meteor. Soc., 139, 1417–1426, https://doi.org/10.1002/qj.2060, 2013. a
Holton, J. R. and Hakim, G. J.: An Introduction to Dynamic Meteorology, in: 5th Edn., Academic Press, Cambridge, 552 pp., ISBN 978-0-12-384866-6, https://doi.org/10.1016/C2009-0-63394-8, 2013. a
Hoskins, B. J. and Coutinho, M. M.: Moist singular vectors and the predictability of some high impact European cyclones, Q. J. Roy. Meteor. Soc., 131, 581–601, https://doi.org/10.1256/qj.04.48, 2005. a
Hoskins, B. J., McIntyre, M. E., and Robertson, A. W.: On the use and significance of isentropic potential vorticity maps, Q. J. Roy. Meteor. Soc., 111, 877–946, https://doi.org/10.1002/qj.49711147002, 1985. a, b, c
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Physica D, 230, 112–126, https://doi.org/10.1016/j.physd.2006.11.008, 2007. a
Isaksen, L., Hasler, J., Buizza, R., and Leutbecher, M.: The new Ensemble of Data Assimilations, ECMWF Newsletter 123, ECMWF, Shinfield Park, Reading, Berkshire, UK, https://doi.org/10.21957/vzbtkbf8, 2010. a, b, c
Joos, H. and Forbes, R. M.: Impact of different IFS microphysics on a warm conveyor belt and the downstream flow evolution, Q. J. Roy. Meteor. Soc., 142, 2727–2739, https://doi.org/10.1002/qj.2863, 2016. a
Judt, F.: Insights into Atmospheric Predictability through Global Convection-Permitting Model Simulations, J. Atmos. Sci., 75, 1477–1497, https://doi.org/10.1175/JAS-D-17-0343.1, 2018. a
Lang, S. T. K., Hólm, E., Bonavita, M., and Trémolet, Y.: A 50-member Ensemble of Data Assimilations, ECMWF Newsletter 158, ECMWF, Shinfield Park, Reading, Berkshire, RG2 9AX, UK, https://doi.org/10.21957/nb251xc4sl, 2019. a
Lang, S. T. K., Dawson, A., Diamantakis, M., Dueben, P., Hatfield, S., Leutbecher, M., Palmer, T., Prates, F., Roberts, C. D., Sandu, I., and Wedi, N.: More accuracy with less precision, Q. J. Roy. Meteor. Soc., 147, 4358–4370, https://doi.org/10.1002/qj.4181, 2021. a
Leutbecher, M. and Lang, S. T. K.: On the reliability of ensemble variance in subspaces defined by singular vectors, Q. J. Roy. Meteor. Soc., 140, 1453–1466, https://doi.org/10.1002/qj.2229, 2014. a
Leutbecher, M. and Palmer, T. N.: Ensemble Forecasting, J. Comp. Phys., 227, 3515–3539, https://doi.org/10.1016/j.jcp.2007.02.014, 2008. a, b
Lillo, S. P. and Parsons, D. B.: Investigating the dynamics of error growth in ECMWF medium-range forecast busts, Q. J. Roy. Meteor. Soc., 143, 1211–1226, https://doi.org/10.1002/qj.2938, 2017. a
Lorenz, E. N.: Deterministic non periodic flow, J. Atmos. Sci., 20, 130–141, https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2, 1963. a
Lorenz, E. N.: Predictability; Does the flap of a Butterfly's wings in Brazil Set Off a Tornado in Texas?, Presented at the American Association for the Advancement of Science, 139th meeting, https://web.archive.org/web/20130612164541/http://eaps4.mit.edu/research/Lorenz/Butterfly_1972.pdf (last access: 11 November 2021), 1972. a
Madonna, E., Wernli, H., Joos, H., and Martius, O.: Warm Conveyor Belts in the ERA-Interim Dataset (1979–2010), Part I: Climatology and Potential Vorticity Evolution, J. Climate, 27, 3–26, https://doi.org/10.1175/JCLI-D-12-00720.1, 2014. a, b, c
Magnusson, L., Nycander, J., and Källén, E.: Flow-dependent versus flow-independent initial perturbations for ensemble prediction, Tellus A, 61, 194–209, https://doi.org/10.1111/j.1600-0870.2008.00385.x, 2009. a
Magnusson, L., Ackerley, D., Bouteloup, Y., Chen, J.-H., Doyle, J., Earnshaw, P., Kwon, Y., Köhler, M., Lang, S., Lim, Y.-J., Matsueda, M., Matsunobu, T., McTaggart-Cowan, R., Reinecke, A., Yamaguchi, M., and Zhou, L.: Skill of medium-range forecast models using the same initial conditions, B. Am. Meteorol. Soc., 103, E2050–E2068, https://doi.org/10.1175/BAMS-D-21-0234.1, 2022. a
McCabe, A., Swinbank, R., Tennant, W., and Lock, A.: Representing model uncertainty in the Met Office convection-permitting ensemble prediction system and its impact on fog forecasting, Q. J. Roy. Meteor. Soc., 142, 2897–2910, https://doi.org/10.1002/qj.2876, 2016. a
Molteni, F. and Palmer, T. N.: Predictability and finite-time instability of the northern winter circulation, Q. J. Roy. Meteor. Soc., 119, 269–298, https://doi.org/10.1002/qj.49711951004, 1993. a, b, c
Molteni, F., Buizza, R., Palmer, T. N., and Petroliagis, T.: The ECMWF Ensemble Prediction System: Methodology and validation, Q. J. Roy. Meteor. Soc., 122, 73–119, https://doi.org/10.1002/qj.49712252905, 1996. a, b
Oertel, A., Boettcher, M., Joos, H., Sprenger, M., and Wernli, H.: Potential vorticity structure of embedded convection in a warm conveyor belt and its relevance for large-scale dynamics, Weather Clim. Dynam., 1, 127–153, https://doi.org/10.5194/wcd-1-127-2020, 2020. a, b
Palmer, T. N., Molteni, F., Mureau, R., Buizza, R., Chapelet, P., and Tribbia, J.: Ensemble prediction, Tech. rep., ECMWF, Shinfield Park, Reading, Berkshire, UK, https://doi.org/10.21957/igxccor4n, 1992. a, b
Palmer, T., Döering, A., and Seregin, G.: The real butterfly effect, Nonlinearity, 27, R123–R141, https://doi.org/10.1088/0951-7715/27/9/R123, 2014. a
Parsons, D. B., Beland, M., Burridge, D. Bougeault, P., Brunet, G., Caughey, J., Cavallo, S. M., Charron, M., Davies, H. C., Diongue Niang, A., Ducrocq, V., Gauthier, P., Hamill, T. M., Harr, P. A., Jones, S. C., Langland, R. H., Majumdar, S. J., Mills, B. N., Moncrieff, M., Nakazawa, T., Paccagnella, T., Rabier, F., Redelsperger, J.-L., Riedel, C., Saunders, R. W., Shapiro, M. A., Swinbank, R., Szunyogh, I., Thorncroft, C., Thorpe, A. J., Wang, X., Waliser, D., Wernli, H., and Toth, Z.: THORPEX Research and the Science of Prediction, B. Am. Meteorol. Soc., 98, 807–830, https://doi.org/10.1175/BAMS-D-14-00025.1, 2017. a
Rabier, F., Järvinen, H., Klinker, E., Mahfouf, J.-F., and Simmons, A.: The ECMWF operational implementation of four-dimensional variational assimilation. I: Experimental results with simplified physics, Q. J. Roy. Meteor. Soc., 126, 1143–1170, https://doi.org/10.1002/qj.49712656415, 2000. a, b
Rennie, M. P., Isaksen, L., Weiler, F., de Kloe, J., Kanitz, T., and Reitebuch, O.: The impact of Aeolus wind retrievals on ECMWF global weather forecasts, Q. J. Roy. Meteor. Soc., 147, 3555–3586, https://doi.org/10.1002/qj.4142, 2021. a
Riemer, M. and Jones, S. C.: Interaction of a tropical cyclone with a high-amplitude, midlatitude wave pattern: Waviness analysis, trough deformation and track bifurcation, Q. J. Roy. Meteor. Soc., 140, 1362–1376, https://doi.org/10.1002/qj.2221, 2014. a
Rodwell, M. J. and Wernli, H.: Animations of uncertainty growth rates from operational ensemble prediction systems, for the time period 20 November 2020–10 March 2021, Research Collection, ETH Zurich, Zurich [video supplement], https://doi.org/10.3929/ethz-b-000605102, 2023. a
Rodwell, M. J., Magnusson, L., Bauer, P., Bechtold, P., Bonavita, M., Cardinali, C., Diamantakis, M., Earnshaw, P., Garcia-Mendez, A., Isaksen, L., Källén, E., Klocke, D., Lopez, P., McNally, T., Persson, A., Prates, F., and Wedi, N.: Characteristics of occasional poor medium-range weather forecasts for Europe, B. Am. Meteorol. Soc., 94, 1393–1405, https://doi.org/10.1175/BAMS-D-12-00099.1, 2013. a, b, c
Rodwell, M. J., Lang, S. T. K., Ingleby, N. B., Bormann, N., Hólm, E., Rabier, F., Richardson, D. S., and Yamaguchi, M.: Reliability in ensemble data assimilation, Q. J. Roy. Meteor. Soc., 142, 443–454, https://doi.org/10.1002/qj.2663, 2016. a, b
Rodwell, M. J., Richardson, D. S., Parsons, D. B., and Wernli, H.: Flow-Dependent Reliability: A Path to More Skillful Ensemble Forecasts, B. Am. Meteorol. Soc., 99, 1015–1026, https://doi.org/10.1175/BAMS-D-17-0027.1, 2018. a, b, c, d, e, f, g
Rodwell, M. J., Hammond, J., Thornton, S., and Richardson, D. S.: User decisions, and how these could guide developments in probabilistic forecasting, Q. J. Roy. Meteor. Soc., 146, 3266–3284, https://doi.org/10.1002/qj.3845, 2020. a
Saetra, Ø., Hersbach, H., Bidlot, J. R., and Richardson, D. S.: Effects of Observation Errors on the Statistics for Ensemble Spread and Reliability, Mon. Weather Rev., 132, 1487–1501, https://doi.org/10.1175/1520-0493(2004)132<1487:EOOEOT>2.0.CO;2, 2004. a, b
Sanders, F.: The evaluation of subjective probability forecasts, Sci. Rept. 5, MIT, Dept. of Earth, Atmospheric and Planetary Sciences, 77 Massachusetts Avenue, Cambridge, MA 02139-4307, USA, 63 pp., 1958. a
Selz, T., Riemer, M., and Craig, G. C.: The Transition from Practical to Intrinsic Predictability of Midlatitude Weather, J. Atmos. Sci., 79, 2013–2030, https://doi.org/10.1175/JAS-D-21-0271.1, 2022. a
Shutts, G. J.: A stochastic kinetic energy backscatter algorithm for use in ensemble prediction systems, Tech. Rep. 449, ECMWF, Shinfield Park, Reading, Berkshire, UK, https://doi.org/10.21957/74ucsdm5c, 2004. a
Stephenson, D. B. and Doblas-Reyes, F. J.: Statistical methods for interpreting Monte Carlo ensemble forecasts, Tellus A, 52, 300–322, https://doi.org/10.1034/j.1600-0870.2000.d01-5.x, 2000. a
Sun, Y. Q. and Zhang, F.: Intrinsic versus Practical Limits of Atmospheric Predictability and the Significance of the Butterfly Effect, J. Atmos. Sci., 73, 1419–1438, https://doi.org/10.1175/JAS-D-15-0142.1, 2016. a
Sutton, O. G.: The development of meteorology as an exact science, Q. J. Roy. Meteor. Soc., 80, 328–338, https://doi.org/10.1002/qj.49708034503, 1954. a
Swinbank, R., Kyouda, M., Buchanan, P., Froude, L., Hamill, T. M., Hewson, T. D., Keller, J. H., Matsueda, M., Methven, J., Pappenberger, F., Scheuerer, M., Titley, H. A., Wilson, L., and Yamaguchi, M.: The TIGGE Project and Its Achievements, B. Am. Meteorol. Soc., 97, 49–67, https://doi.org/10.1175/BAMS-D-13-00191.1, 2016. a, b
Tiedtke, M.: A Comprehensive Mass Flux Scheme for Cumulus Parameterization in Large-Scale Models, Mon. Weather Rev., 117, 1779–1800, 1989. a
Tribbia, J. J. and Baumhefner, D. P.: Scale Interactions and Atmospheric Predictability: An Updated Perspective, Mon. Weather Rev., 132, 703–713, https://doi.org/10.1175/1520-0493(2004)132<0703:SIAAPA>2.0.CO;2, 2004. a, b
Ván̆a, F., Düben, P., Lang, S., Palmer, T., Leutbecher, M., Salmond, D., and Carver, G.: Single Precision in Weather Forecasting Models: An Evaluation with the IFS, Mon. Weather Rev., 145, 495–502, https://doi.org/10.1175/MWR-D-16-0228.1, 2017. a
Wedi, N. P., Polichtchouk, I., Dueben, P., Anantharaj, V. G., Bauer, P., Boussetta, S., Browne, P., Deconinck, W., Gaudin, W., Hadade, I., Hatfield, S., Iffrig, O., Lopez, P., Maciel, P., Mueller, A., Saarinen, S., Sandu, I., Quintino, T., and Vitart, F.: A Baseline for Global Weather and Climate Simulations at 1 km Resolution, J. Adv. Model. Earth Sy., 12, e2020MS002192, https://doi.org/10.1029/2020MS002192, 2020. a
Wernli, H. and Davies, H. C.: A Lagrangian-based analysis of extratropical cyclones. I: The method and some applications, Q. J. Roy. Meteor. Soc., 123, 467–489, https://doi.org/10.1002/qj.49712353811, 1997. a, b, c
Wernli, H. and Schwierz, C.: Surface Cyclones in the ERA-40 Dataset (1958–2001), Part I: Novel Identification Method and Global Climatology, J. Atmos. Sci., 63, 2486–2507, https://doi.org/10.1175/JAS3766.1, 2006. a
- Abstract
- Introduction
- Models, data, and methods
- Uncertainty growth rates during cyclogenesis
- Forecast reliability
- Sensitivity experiments to quantify sources of uncertainty in the ECMWF ensemble
- Summary and conclusions
- Appendix A: Forecast reliability
- Appendix B: Derivation of the Lagrangian growth rate equation
- Appendix C: Variance spectra for the sensitivity experiments
- Code and data availability
- Video supplement
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References
- Abstract
- Introduction
- Models, data, and methods
- Uncertainty growth rates during cyclogenesis
- Forecast reliability
- Sensitivity experiments to quantify sources of uncertainty in the ECMWF ensemble
- Summary and conclusions
- Appendix A: Forecast reliability
- Appendix B: Derivation of the Lagrangian growth rate equation
- Appendix C: Variance spectra for the sensitivity experiments
- Code and data availability
- Video supplement
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References